
A CUDA (Compute Unified Device Architecture) – az NVIDIA grafikus processzorainak általános célú programozására használható környezet.
A GPU mint parallel adatfeldolgozó
Napjainkban minden területen fontos szempont, hogy a kitűzött feladatokat a lehető legrövidebb idő alatt meg lehessen oldani. Így nagy szerepe van a már meglévő algoritmusok párhuzamosításának. Ennek köszönhetően egyre elterjedtebbek a többprocesszoros gépek, melyek egyszerre számos folyamatot képesek kezelni. Amíg a CPU-k csupán néhány szálat tudnak valós időben egymástól függetlenül futtatni, addig a GPU-k nagyságrendekkel nagyobb számú feladatot végeznek el egyszerre. Az eredetileg grafikus feladatokra szánt hardver modellezési és képalkotási feladataiból adódóan nagy számítási teljesítménnyel rendelkezik, amit ma már az általános célú algoritmusok megvalósítása esetén is fel lehet használni.
A GPU architektúra
A GPU-k felépítése a parallel működésüknek köszönhetően összetettebbek a hagyományos CPU-khoz képest. A tényleges számítási műveleteket az úgynevezett multiprocesszorok (MP) végzik, melyek mindegyike önálló regiszterekkel és osztott memóriával rendelkezik. Az itt található memória akár 100-szor is gyorsabb lehet a videókártya globális memóriájától. Az MP-ken belül további CUDA magok találhatók. A párhuzamos feldolgozás érdekében az MP-ken warpok vannak definiálva, melyek meghatározott számú folyamatot képesek egyszerre lefuttatni.SIMT architektúra
Az SIMT (Single Instruction, Multiple Thread) architektúra egy az SIMD (Single Instruction, Multiple Data) GPU-ra tervezett speciális változata. Amíg az SIMD rendszerek adatszintű párhuzamosítást végeznek, egy műveletet egyszerre több adaton is végrehajtanak, addig itt a hangsúly azon van, hogy több egymástól független szál is létrehozható legyen, melyeken keresztül irányított adatszintű parallelizáció végezhető.A CUDA programozási modell
Az NVIDIA arra alkalmas GPU-it többek között a CUDA programozási modellben definiált szemlélet alapján, a hozzá tartozó eszközökkel lehet programozni. Ennek a modellnek köszönhetően a párhuzamos futtatás egy egyszerű függvény meghívásával történik. Az ilyen függvényeket kernel függvényeknek nevezzük. A kernel függvények két lényeges dologban térnek el a többitől:- __global__ minősítővel rendelkeznek,
- <<<, >>> operátort tartalmaznak.
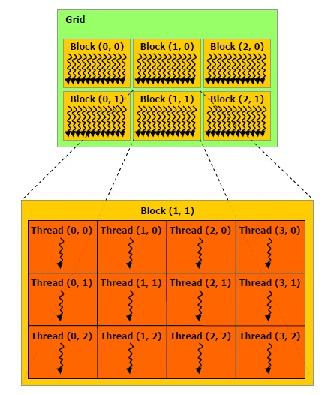
A CUDA alkalmazások kétféle kitüntetett függvényt ismernek, az egyik ilyen a __global__ , a másik pedig a __device__ minősítővel ellátott. Az előbb ismertetett kernel függvény csak __global__ típusú lehet és ugyanez fordítva is igaz. A __device__ metódusok pedig bármilyen a GPU-n futó programrészből elérhető függvények. A kernel speciális <<<, >>> operátorának paramétereiben határozzuk meg hány szálat szeretnénk futtatni, azokat hány blokkba osztva. Ha az algoritmusunk megköveteli, explicit módon megadható, hogy mennyi osztott memóriát szeretnénk lefoglalni a maximális megengedett értéken belül. A blokkokból úgynevezett grid jön létre. A gridet leszámítva, mind a blokkok, mind pedig a szálak lehetnek egy-, kettő-, illetve háromdimenziós struktúrák, a grid egy-, illetve kétdimenziós lehet [11]. A többdimenziós struktúrák az SIMT architektúrából adódóan lényegesek, ugyanis így thread orientált adatszintű párhuzamosítást tudunk elérni. Az egyes elemek elérését beépített változók segítik.
A szálak azonosítójának lekérdezése, azok tömb szerkezetbe való elhelyezkedése esetén:
blockDim.x * blockIdx.x + threadIdx.x.
Korábban említésre került, hogy a GPU-n található osztott és globális memória is. Ezek a CUDA modell szerint a következőképp oszlanak meg:
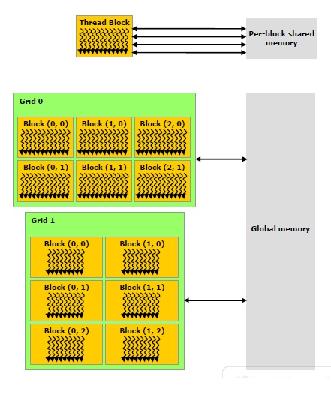
- Minden szálhoz tartozik lokális memória.
- A blokkok osztott memóriával rendelkeznek.
- A globális memória bárhonnan elérhető.
Egyéb modellek
A CUDA modellen kívül egyéb környezetek is rendelkezésre állnak, melyek a GPU programozására lettek megalkotva. Az egyik ilyen az OpenCL, mely teljes mértékben nyílt forráskodú eszközt ad azok kezébe, akik alkalmazni szeretnék a GPU-k nagy számítási kapacitását. A másik platform a Microsoft DirectX 11-es verziójában megtalálható DirectCompute, melynek szerepe szintén a GPU-k erejének alkalmazása az általános feladatok körében. A leglényegesebb különbség ezen két eszköz és a CUDA modell között, hogy csak ezzel a kettővel lehet elérni az egyéb gyártótól származó GPU-kat is.Nyelvi elemek
A CUDA nyelv lényegében a C/C++ nyelv kiegészítése és bizonyos szempontból szűkítése is, bár a kártyák és a technológia fejlődésével mára a C++ nyelv legnagyobb része használható CUDA kódban is. A kiegészítés lényegében a minősítőkből és jó pár saját típusból áll.<<< , >>> operátor
A kernel függvényeketfüggvénynév <<< gridDim, blockDim >>> (fügvény_paraméterek)
alakban kell meghívni
Függvény minősítők
- __global__ : a kernel függvény, vagyis a GPU-n futó kód, a gazda kódból hívható
- __device__ : GPU-n futó függvény kódja, csak GPU kódból hívható
- __host__ : gazda kód, csak gazda kódból hívható, melyre csak akkor van szükség, ha gazda kódot írnánk CUDA forrásfájlba
- __noinline__, __forceinline__ : jelzés a fordítónak, hogy az adott függvényt inline vagy nem inline módon szeretnénk fordítani
Változó minősítők
- __device__ : a változó az eszköz memóriában jön létre (eszköz kódban minden változó az eszköz memóriában jön létre)
- __constant__ : konstans memóriában foglalt változóinak
- __restrict__ : pointerekre vonatkozó megkötés, mely jelzi a fordító számára, hogy nincs kereszthivatkozás az egyes pointerek között, ezért nyugodtan betölthetőek regiszterekbe
- __shared__ : ez jelzi a GPU kódban ha valamelyen adatnak a blokkon belüli osztott memóriában a helye
Típusok
- beépített vektor típusok: charN, shortN, intN, longN, longlongN, floatN, doubleN, ahol N lehet 2, 3 és 4 eleműek és elemeiket elemeiket az x,y,z,w tagokkal érhetjük el
- dim3: három elemű uint típus, mely a nem megadott elemeit 1-re inicializálja
Beépített változók
- gridDim: dim3 típusú, a grid dimenzióját adja meg
- blockDim: dim3 típusú, a blokk dimenzióját adja meg
- blockIdx: uint3 típusú, a futó blokk számát adja meg
- threadIdx: uint3 típusú, a futó szál számát adja meg
- warpSize: int típusú és a warp méretét adja meg
Szinkronizációs függvények
- __syncthreads() : biztosítja, hogy az elvégzett műveletek eredményei láthatóvá válnak a többi szál számára is, valamit megvárja, hogy a többi szál is eljusson erre a pontra, ha a végrehajtás nem minden szálon volt egyforma hosszú
- __syncthreads_count(int predicate), __syncthreads_and(int predicate), __syncthreads_or(int predicate) : ugyanaz mint fent, de a predicate alapján kiértékeli a szálakat és megadja a számukat, vagy pedig össze-éseli vagy össze-vagyolja a kiértékelés eredményét
Atomikus függvények
Olyan függvények melyek egy utásítás alatt olvasnak ki egy adatot, végeznek rajta egy műveletet majd teszik vissza a kiolvasott elem helyére. Az elérhető műveleteket: összeadás, kivonás, csere, minimum, maximum, inkrementálás, dekrementálás, összehasonlítás-és-csere, és, vagy, kizáró-vagy. Ezen műveletek nagy része csak egész típusokra elérhető. Lebegőpontos típusra csak a csere és az összeadás működik.Más nyelvek
A CUDA platformhoz számos programozási nyelven léteznek kötések, melyek legtöbbje továbbra is a CUDA fordítót használja a tényleges GPU kód fordításához.Fordítás
A CUDA SDK az nvcc saját fordítóval érkezik, mind Windows mind Linux operációs rendszerekre. Ez az egy fordító végzi a gazda kódok fordítását is. Működése a következő: lefordítja a GPU kódot majd a CPU kódba a <<< , >>> helyére behelyettesíti a megfelelő CUDA hívásokat. A CPU kódot a továbbiakban pedig átadja az adott platformon alapértelmezett fordítónak. Ez Windows rendszereken a Visual C++ fordító, míg Linux rendszereken a GCC.
A linkelés során két lehetőség is van. A GPU kód vagy egy könyvtárként valósul meg és bekerül az alkalmazásba, vagy pedig úgynevezett PTX kód keletkezik belőle, melyet a GPU meghajtó képes fordít le gépi kódra futás előtt. Utóbbi előnye, hogy a kód újrafordítás nélkül, még nem létező eszközökön is futhasson a jövőben.
A fordítóból létezik 32bit-es és 64bit-es változat is. Mindkettő képes 32bit-es és 64bit-es kódot is fordítani a GPU, de 32bit-es GPU kód csak 32bit-es CPU kóddal együtt, 64bit-es GPU kód pedig csak 64bit-es CPU kóddal futtatható együtt.
Kompatibilitás
CUDA programozásnál többféle kompatibilitást is figyelembe kell venni. A leglényegesebb a hardver számítási kompatibilitása (compute compatibility). Ez a grafikus hardver verziószáma, mely azt írja le, hogy a C/C++ mely nyelvi elemeit ismeri fel és a hardver mely utasítás készlet futtatására képes. A kártyák fejlődése során számos kezdetben nem létező funkcionalitás került a nyelvbe és a fordítóba is, hogy a hardver növekedő teljesítményét és kapacitását minél inkább ki lehessen használni.
A teljesség igénye nélkül néhány példa:
- atomikus egész műveletek, később lebegőpontos műveletek
- dupla pontosságú lebegőpontos számítás
- C++ osztályok kezelése, template-ek kezelése
- indítható szálak és blokkok mennyiségének növelése
A C++ támogatás kérdése természetesen csak a GPU-s kódrészletekre vonatkozik, a CPU-n futó kódot ugyanis az adott platformhoz tartozó C++ fordító kezeli. A számítási kompatibilitást a fordítás során meg lehet adni, mely így a nem támogatott elemekre vagy hibát jelez, vagy pedig kevésbé optimalizáltabb gépi kódot fordít, hogy a régebbi eszközön is lefusson a program.
Memória
A CUDA rendszer több memóriát különböztet meg, melyek kapacitás szerint csökkenő, de gyorsaság szerint növekvő sorrendben a következők:
- rendszer memória: az alaplapon található a teljes rendszer számára elérhető memória
- eszköz memória: a videokártyán található memória, elsősorban az GPU kód számára elérhető memória
- osztott memória: a GPU-n indított szálblokkok számára elérhető közös memória
- regiszterek: szálak változóinak fenntartott memória
A rendszer ezen kívül támogat még különböző címzési eljárásokat is melyek heterogenizálják a kódot, és gyorsíthatják a memória műveleteket egyes esetekben:
Lap-zárolt rendszermemória
Ez a rendszer memória olyan elérését teszi lehetővé a program számára, melyet az operációs rendszer nem helyezhet át lapozással. Ez lehetővé teszi, hogy a program GPU-n való futtatással párhuzamosan is tudjon másolni az eszköz memóriájába. Lehetővé teszi, hogy a rendszer memóriájának címtere az eszközről is elérhető legyen, ezáltal elkerülve a másolást.A GPU-k teljesítménye
A GPU-k maximális teljesítményüket a parallel alkalmazások futtatásakor képesek elérni, ezért is fontos kérdés, hogy mennyire lehet egy algoritmust párhuzamosítani.Amdahl törvénye
Meg kell tudnunk mondani, hogy érdemes-e egy probléma párhuzamosításával foglalkozni. Erre a kérdésre ad választ Amdahl törvénye, mely egy becslést ad arra vonatkozóan, hogy maximum mekkora sebességnövekedésre számíthatunk. Amdahl törvénye:
S=1/((1-P)+(P/N)), ahol:
- S a várható sebességnövekedés,
- P a párhuzamosítható kód teljes szekvenciális végrehajtási idejének tört része,
- N a processzorok száma, amelyen a párhuzamos kód fut.
Például elég nagy N-et választva az egyenlet a következőképpen alakul:
S=1/(1-P)
Ha a program 3/4 része párhuzamosítható, akkor az iménti egyenletből azt kapjuk, hogy 4-szeres teljesítménynövekedés érhető el.
Multi-GPU rendszerek
További teljesítménynövekedés érhető el, ha az NVIDIA SLI (Scalable Link Interface) technológiának köszönhetően több GPU-t is összekötünk egyetlen rendszeren belül, jelenleg maximálisan négy darabot.Fejlesztési követelmények
A fejlesztés során fontos, hogy vegyük figyelembe a GPU architektúra főbb jellemzőit. A kártya globális memóriája akár 100-szor is lassabb lehet bármely más, a GPU-n található memóriánál, ami nagy mértékben lecsökkenti a műveletvégzés sebességét. Ennek érdekében fontos, hogy kerüljük a sűrű másolási műveleteket a host (CPU) és a device (GPU) memóriája között. Hatékony adatmozgatáshoz törekedjünk egyszerre nagyobb méretű blokkok áthelyezésével csökkenteni a szükséges adatküldések számát. A GPU-n átlagosan nagyobb sebességgel értékelődnek ki a függvények, mint amilyen gyorsan meg tudnánk határozni, hogy pontosan hány darab folyamatra van ténylegesen szükség az adott probléma kiszámításához. Pontosan ezért a fel nem használt folyamatoktól eltekintünk.Hardveres megszorítások
Figyelnünk kell arra, hogy az architektúra fejlődésével újabb és újabb lehetőségek nyílnak meg a fejlesztők előtt, hogy összetettebb és hatékonyabb programot készíthessenek. Az architektúra specifikus tényezők azonban mindig az újabb GPU-khoz lesznek kötve. Így bizonyos funkciók elérhetetlenek lesznek a régebbi GPU-k számára. A újabb típusok ismerete, mint például a dupla precíziós számok ábrázolása olyan dolog, amit manuálisan a programozó nehezen pótolhat, ám bizonyos függvények és eljárások kisebb-nagyobb munkával, de reprodukálhatóak a régebbi architektúra megkötései ellenére is. Figyelembe kell venni, hogy milyen felhasználói bázisba szánjuk az alkalmazást, hogy tudjuk milyen hangsúlyt kell fektetnünk ezekre a megkötésekre.
A számítási kompatibilitás mellett érdemes figyelni az adott hardver kapacitására is. Különböző memória méretek miatt, indítható blokkok és szálak száma. Az egy időben végrehajtott warp-ok száma. Ezeket nagyon könnyen megtudhatjuk a beépített eszköz lekérdező függvények segítségével. Ha hordozható kódot szeretnénk akkor érdemes ezeket az adatokat még a szálak méretezése előtt lekérni és ez alapján beosztani őket.
A VRAM mennyisége pedig akkor jelent korlátot, hogy nagy mennyiségű adatot szeretnénk feldogozni, ugyanis a bemeneti értékeknek és az eredménynek is el kell férnie a memóriában, ezért kevés memória esetén sok másolgatás miatt veszthetünk a teljesítményből. Szerencsére a technológia fejlődésével már aszinkron memóriamásolásra is van lehetőség, mely jelentősen gyorsíthat az ilyen eseteken.