
A Matlabot igen gyakran nagy számításigényű tudományos számítások elvégzéséhez is használják, ehhez elengedhetetlen a számítások elosztásának támogatása, melyre toolbox segítségével nyílik lehetőség. Matlaban párhuzamos, elosztott programok írásához a Distributed Computing Toolbox és a MATLAB Distributed Computing Engine használható. Azt a feladatot amit szeretnénk párhuzamosan elvégezni a Matlabban job-nak nevezik. Egy job taszkokból áll, melyek lehetnek különbözőek vagy egyformák. Azt a Matlab példányt amelyben a jobot és taszkjait definiálják azt szokták kliensnek nevezni. A jobok és taszkok definiálásához használatos a Distributed Computing Toolbox és a Distributed Computing Engine az az eszköz amely elvégzi a jobok futtatását, a taszkok kiértékelését és az eredményt visszaadja a kliensnek. További fontos része a rendszernek a job mannager, amely a taszkok szétosztását végzi az Engine-t futtató Matlab példányok, vagy ahogy a dokumentációban nevezik a worker-ek között. (Nem feltétlenül szükséges a Math- Works által készített job managert használni, ez kicserélhető más megvalósításokra.)
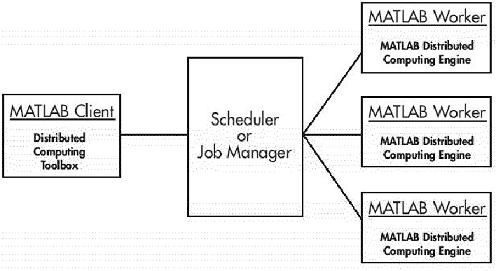
2. ábra. A párhuzamos számításokat végző rendszer felépítése.
Tehát a számítások futtatásának menete a következő: a kliensek definiálják a jobokat és azok taszkjait, ezután a job manager-hez fordulnak amely szétosztja a taszkokat a workerek között, miután az adott worker lefutatott egy taszkot az eredményt visszaadja a job managernek és kap egy újabb taszkot, ha az adott job összes taszkja lefutott akkor a job manager visszaadja kliensnek az eredményt. Több job manager is lehet telepítve egy rendszerben, és a kliensek bármelyikhez fordulhatnak, de az adott worker példány mindig egy manager-hez van beregisztrálva. (Teszteléshez akár egy gépre is lehet telepíteni mindegyik komponenst, akár több példányban is.)
A kliens a job manager-rel kommunikálni a job manager objektum metódusain keresztül tud, és habár nem feltétlenül szükséges a workerekkel közvetlenül kommunikálni azért a worker objektumokon keresztül azokkal is lehet. Amikor a kliens létrehoz egy job-ot az a job manager adat területén jön létre, és a job objektumon keresztül tud a kliens hozzáférni, hasonlóan a taszkokhoz.
Egy egyszerű példa
A következő egyszerű példával megpróbálom bemutatni a jobok és taszkjaik
létrehozásának, és futatásuknak lépéseit.
Mindegyik taszk az input tömb elemeit összegzi.
-
Először is meg kell találni a job managert a hálózaton a findResource parancs segítségével.
jm = findResource('scheduler','type','jobmanager', ...
'name','MyJobManager','LookupURL','JobMgrHost');A job managert amely a MyJobManager néven lett regisztrálva a JobMgrHost gépen a jm fogja reprezentálni.
-
A második lépés a job létrehozása:
j = createJob(jm);
-
Ezután következik a taszkok elkészítése:
createTask(j, @sum, 1, [1 1]);
createTask(j, @sum, 1, [2 2]);
createTask(j, @sum, 1, [3 3]); -
Ezután be kell rakni a jobot a futtató sorba, ahonnan majd akkor kerül ki ha lesz szabad worker.
submit(j);
-
Majd meg kell várni a job lefutását, az eredményt:
waitForState(j)
results = getAllOutputArguments(j)
results =
[2]
[4]
[6] -
Végül a jobot el kell távolítani a job managerből:
destroy(j);
Amikor egy egyszerű függvényt szeretnénk kiértékelni (mint az előző példában), akkor választhatunk egy egyszerűbb megoldást: a dfeval függvényt. Ilyenkor nem kell nekünk létrehozni külön a jobot és taszkokat. Így a következő egy sorral ugyan azt az eredményt érhetjük el mint az előző példával.
results = dfeval(@sum, [1 1] [2 2] [3 3])
results =
[2]
[4]
[6]
A dfeval(@fv; param1; param2; ...; paramn) hívás n taszkot hoz létre a paraméterek számának megfelelően. Mindegyik taszk a fv-egy példányát futtatja le valamelyik paraméterezés szerint.