
Monádok
Ebben a fejezetben megpróbálunk egy rövid összefoglalót adni a Haskell talán legegzotikusabb fogalmáról, a monádról. A fejezetnek nem célja a monádok teljes mélységű feltárása, inkább néhány (az eddiegekhez képest kicsit összetettebb) példát mutatunk be, bevezető és egyben gondolatébresztő jelleggel. Elsőként Moggi figyelt fel arra, hogy monádokkal különböző imperatív programozásból ismert nyelvi elem integrálható a funkcionális világba (kivételkezelés, állapottárolás, stb.) Azonban annak aki nem járatos a kategóriaelmélet rejtelmeiben talán valamivel emészthetőbbek Wadler cikkei ([2]). Tulajdonképpen azt mondhatjuk, hogy mindazt ami nem fér bele a tisztán funkcionális világba, monádokon keresztül hozzák be a nyelvbe. Monádok állnak az IO műveletek mögött (úgyis mint a felhasználói interfész, GUI, kezelése), sőt a GHC konkurens programozást támogató része is monádokon alapszik. Valamirevaló funkcionális programozó tehát nem mehet el tétlenül a monádok mellett.
Monadikus osztályok
A Haskell Prelude-je több monadikus osztályt definiál. Ezek az osztályok a kategóriaelmélet monád fogalmának és az ahhoz szükséges struktúráknak Haskell megfelelői. A használatukhoz azonban nincs szükség az absztrakt matematikai háttér mélyebb ismeretére (megértésükhöz igen). A fejlesztők a monádokhoz kapcsolódó fogalmak közül hármat integráltak a rendszerbe, mindegyikhez egy-egy osztályt rendelve (Functor, Monad és MonadPlus), ezeket közös néven monadikus osztályoknak nevezzük.
Monadok: A monadikus konstrukció segítségével a Haskell lusta környezetében is lehetségessé vált a mellékhatások szekvenciájának megtartása. Hogyan? Ha a nyelv kiértékelési stratégiája ellenünk van, mi az, amivel mégis garantálhatjuk, hogy a kifejezések adott sorrendben értékelődjenek ki? A monadikus megoldás elve egy ügyes építményhez hasonlít, ami úgy csomagolja dobozokba a sorrendben végrehajtandó adatokat, hogy a lusta kiértékelő ne tudja máshogyan kicsomagolni őket, csak az általunk kívánt sorrendben. Ez másfelől azt garantálja, hogy a monádban tárolt állapothoz vagy bármi egyébhez csak egyfajta sorrendben (single-threaded) férhetünk hozzá, ami az imént említett jó elválasztás alapja.
Matematikai háttér
A kategóriaelmélet 1945-ös felfedezését Samuel Eilenberg és Saunders Mac Lane matematikusok nevéhez köthetjük, akik algebrai topológiával foglalkozva találták ki a kategóriaelméletet és kezdték el leírását. A 60-as évek körül a kategóriaelméletet az algebrai topológiában, algebrai geometriában, univerzális algebrában egyre többen használták. Ekkorra már tudták, hogy a kategóriaelmélet több mint bizonyításokra kényelmesen használható nyelv (hiszen saját tételei is vannak), és a megnövekedett érdeklődésnek köszönhetően szépen fejlődött. Máig több más területen is alkalmazhatónak mutatkozott: az elméleti számítástudományon kívül a matematikai fizikában is. Mindemellett úgy tűnik, a filozófusok is szemet vetettek a kategóriaelmélet „bájaira”.
A matematika több területén is előfordul, hogy valamiféle objektumokat és köztük fennálló leképezéseket tanulmányozunk. Ilyenek például a halmazok és függvények, a vektorterek és lineáris transzformációk, csoportok és csoport homomorfizmusok. A kategóriaelmélet alapötlete a különféle objektumok és leképezések fogalmának általánosítása. Ráadásul az általánosítást úgy teszi, hogy az objektumok belső szerkezetét „elfelejti”.
Kategória
A kategóriaelmélet alapfogalmai tehát az objektum és a morfizmus. A halmazok, vektorterek, csoportok – belső szerkezetet nem feltételező – általánosítását objektumoknak nevezzük. A függvények, lineáris transzformációk, homomorfizmusok általánosítását morfizmusoknak nevezzük. A morfizmusok tehát általánosított leképezések, lényegük, hogy valahonnan valahova (objektumból objektumba) képeznek, de a leképezés módjáról – ahogyan az objektumok belső szerkezetéről sem – a morfizmusok esetében sem jelentünk ki semmit. A morfizmusokat ezért nyilaknak is szokták nevezni és ábrázolni. Ezek után definiálhatjuk az objektumok és morfizmusok fölé épülő kategória fogalmát.
Definíció
Definíció – KATEGÓRIA- A C = (OC,MC,TC,oC,IdC) kategória egy struktúra, amely a következőkből áll :
- OC objektumok osztálya (egyszerűsítésként halmaznak tekintjük)
Jelölésük pl. A,B
Az objektumokat pontoknak képzelhetjük el (belső szerkezetük nem ismert). - MC morfizmusok osztálya (egyszerűsítésként halmaznak tekintjük)
Jelölésük pl. f
A morfizmust két objektum közötti nyílnak képzelhetjük el. - TC a morfizmusok típus-információja, amely egy TC része MC x OC x OC relációval írható le.
Azt az objektumot, amelyből az f morfizmus kiindul forrásnak – jelölése src(f) –,
amelyikbe pedig érkezik, azt képnek – jelölése tgt(f) – nevezzük.
A morfizmus típusán forrás- és képobjektumát értjük. Minden morfizmusnak van típusa, ezt a TC relációval kifejezve: minden f eleme MC -hez létezik A ,B eleme OC hogy (f , A , B) eleme TC Minden morfizmus típusa egyértelmű.
Egyszerűsített jelölés: f: A -› B
(Megjegyzés: A kategória definíciójának a morfizmusok típusait leíró részét csak azért lehet relációként definiálni, mert MC és OC osztályokat egyszerűsítésként halmazoknak tekintettük. Precízebb lenne src és tgt operátorokat definiálni TC helyett, ezeket). - oC kompozíció operátor
A továbbiakban a kategória nevére utaló C-indexet elhagyva ?-ként beszélünk róla.
o: MC x MC -› MC (o a kompozíció)
Morfizmusok kompozíciója: g o f az f és g morfizmusok egymás után alkalmazásával kapott morfizmus, akkor értelmezett, ha f képobjektuma megegyezik g forrásobjektumával. Ekkor az eredményként kapott g o f morfizmus forrása f forrása, képe pedig g képe lesz. f : A -› B és g : B-› C akkor g o f : A-› C
Jelölései: g o f = g f = f ; g
(A ; jelölés a programozásban használt szekvencia operátorhoz hasonló jelentést hordoz, előnye, hogy a függvények egymás után alkalmazásának sorrendjét nem fordítja meg, mint a matematikából származó ? operátor.)
A kompozíció operátorra teljesülnie kell az asszociativitás-szabálynak: bármely komponálható f,g,h eleme MC -re: h o (g o f) = (h o g) o f. - IdC identitás operátor
IdC: OC -› MC
IdC(A)=idA
Az identitás operátor minden A objektumhoz egyértelműen hozzárendel egy idA: A -› A morfizmust, az identitás morfizmust.
Az identitás morfizmusokra teljesülnie kell az identitás-szabálynak: bármely f: A -› B-re: idB o f = f = f o idA
A kategóriákat félkövér betűvel, betűkkel (vagy számmal) jelöljük, pl. A, B, C, 3, Set, Group, Graph, Erl.
3 kategória
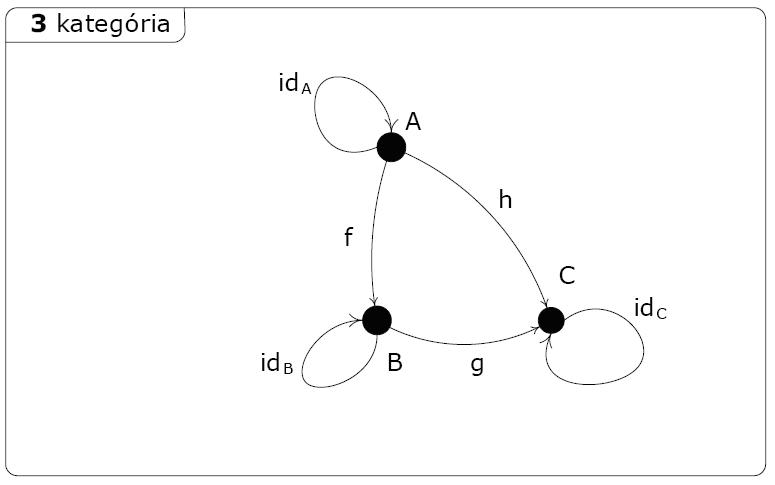
Nézzünk néhány példát kategóriákra. A legegyszerűbb kategória a 0 kategória, ebben sem objektumok, sem morfizmusok nincsenek, a definícióban szereplő feltételeket ürességével elégíti ki. A triviális példák között következik az 1 kategória, amelynek egy objektuma és ehhez szükségképpen az egyetlen objektumból az egyetlen objektumba menő identitás) morfizmusa van, az asszociativitás és identitás-szabály (axiómák) erre is egyszerűen teljesülnek. 2 kategóriának nevezzük a 2 objektumból, 2 identitás- és 1 az egyik objektumból a másikba mutató morfizmusból álló kategóriát; itt a kompozíció operátor csak egyféleképpen definiálható és könnyen belátható az axiómák teljesülése is. A 3 kategória 3 objektumból és 3 identitás-, valamint 3 „rendes” morfizmusból áll (lásd ábrán), a kompozíció operátor ezek alapján egyértelműen adódik (az egyetlen nem-triviális és mégis komponálható eset: f o g = h) , az axiómák is teljesülnek, így 3 tényleg kielégíti a kategória fogalmát. Természetesen ez utóbbi kategóriát másképpen is definiálhattuk volna, több morfizmus is lehetne benne, akár ugyanazon két objektum között is, de mi önkényesen ezt a definíciót választottuk. Arra azonban vigyázni kell, hogy ha két morfizmus komponálható, akkor legyen olyan morfizmus a kategóriában, amit ezen kompozíció eredményéül definiálhatunk, pl. a 3-ból a h elhagyásával kapott struktúra már nem kategória, mert f és g kompozíciója nem létezik benne.
A nem triviális példák között említhetjük a Set kategóriát, amelynek objektumai halmazok, morfizmusai pedig teljes függvények. A Set kategória kompozíció operátorát a függvények kompozíciójával definiáljuk, az identitás morfizmusok pedig a halmaz minden eleméhez önmagukat rendelő függvények. A lenti ábrán a Set kategória egy részletét láthatjuk, amely csak érzékeltetni próbálja a kategória jellegét, de csak néhány (véges, ill. végtelen) halmaz és néhány morfizmus van ábrázolva rajta.
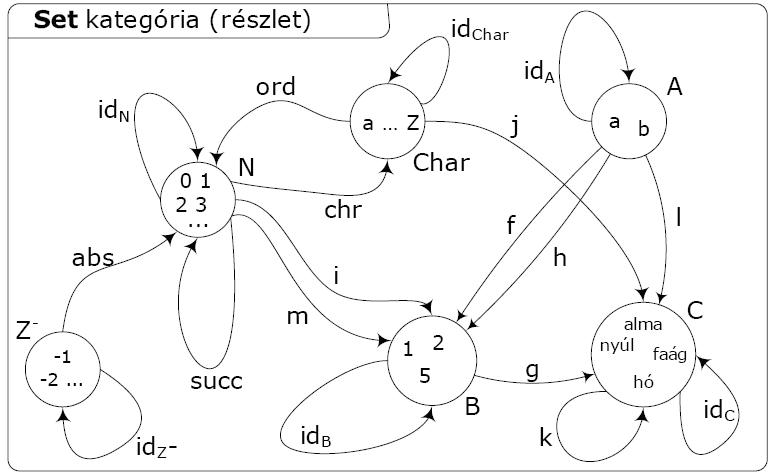
Set kategória
A Set kategória esetében szem előtt kell tartanunk azt, hogy bár ebben a speciális esetben az objektumoknak van belső szerkezete, azaz vannak elemei, amint az az ábrán is látszik, ennek azonban a kategóriaelméleti tárgyalásánál nincsen jelentősége. Ha a tárgyalás során valamikor is felhasználjuk az elemek fogalmát, akkor kilépünk a kategóriaelméletből, de más tárgyalási szinten – például halmazelméletet használva – természetesen ilyen is előfordulhat. Ami még látszik az ábrából, az az, hogy a Set kategória objektumai az összes halmazok, így pl. a 3 elemű B halmaz, a véges elemszámú, elemekként betűket tartalmazó Char halmaz és a végtelen, a természetes számokat tartalmazó N halmaz is objektumok a kategóriában. Minden objektumhoz (halmazhoz) az identitás morfizmust is feltüntettem. Az objektumok között mindenféle morfizmusok (a Set esetében ezek függvények) mennek, két objektum között akár többféle is lehet, ahol a függvény típusa ugyanaz, a leképezés viszont legalább az értelmezési tartomány egy elemére különbözik. Lehet például m függvény a minden természetes számhoz 1-et rendelő, míg i a 0 kivételével minden természetes számhoz 1-et és 0-hoz 5-öt rendelő függvény. Az objektumból önmagába is mehet az identitás-morfizmuson kívül más függvény, például N esetén a succ, vagy C-re definiálhatnánk egy egyszerű, az elemeket permutáló függvényt.
Megjegyzés: a Set kategória esetében az objektumok – az összes lehetséges halmaz – korántsem férnek bele egy halmazba. A Russel-paradoxon miatt az összes halmazok nem halmazt, hanem osztályt alkotnak. A Setnél nem helytálló tehát a kategória definíciójában az objektumokat és a morfizmusokat osztályok helyett egyszerűsítésként halmazoknak tekinteni. A kategória precíz definíciójában OC és MC halmaz helyett osztályok, ill. TC nem reláció hanem 2 operátor (ld. a kategória definíciójában szereplő megjegyzést).
A kategóriaelmélet gondolkodásmódját szemléltetendő érdemes megnézni az injektív függvény morfizmusokra általánosított változatának, a monomorfizmusnak a definícióját.
Emlékeztetőül: injektív függvénynek nevezzük az olyan függvényt, amely az értelmezési tartomány bármely két különböző pontjához különböző értéket rendel, azaz egyértelmű, ezt formálisan kifejezve: f injektív, ha f(x)= f (y) akkor x=y . Jól látható, hogy az injektivitás
definíciójában a függvény értelmezési tartományának és értékkészletének elemei fontos szerepet játszanak. A C kategóriában az f: B -› C morfizmus monomorfizmus, ha bármely A objektumra és g: A -› B, h: A -› B morfizmusokra f o g= f o h akkor g=h . A kategóriaelméletben gyakran használnak diagramokat összefüggések szemléltetésére, a monomorfizmus definíciójának alapállása „diagramnyelven” így néz ki:
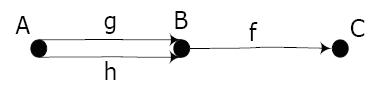
Figyeljük meg hogyan írjuk le „kívülről” morfizmusokkal azt, amit eddig „belülről” elemekkel fejeztünk ki, hogyan válik absztraktabbá, általánosabbá az injektivitás fogalma.
Kategóriák a programozásban
Hogyan alkalmazható a kategóriaelmélet a számítástudományban? A kategória fogalmát egy kis fantáziával szemlélve hasonlóság fedezhető fel a kategóriák és a programozási nyelvek között. Hogyan? Az objektumokat megfeleltethetjük a programozásban használt adattípusoknak, ahogyan azok a típusos nyelv esetén a nyelvben és a leírt programban, vagy pl. a Haskell esetén a programozó, ill. programtervező gondolataiban jelen vannak. A morfizmusok a program függvényei, vagy egy egész modul, vagy az egész program (funkcionális nyelvekben ugyanis függvénynek tekinthető) is lehet.
Monádok a funkcionális programozásban
Motiváció
Gyakori probléma szinte minden funkcionális nyelvben, így Haskellben is, hogy ha valóban szekvenciális jellegű műveletsort kell a programban leírni, az kitekert formát ölthet a változónévérték kötések egyszeri és változtathatatlan volta miatt. Gyakran látunk pl. ilyen programrészletet:
Adat1 = akció1(Adat0),
Adat2 = akció2(Adat1),
Adat3 = akció3(Adat2),
Adat4 = akció4(Adat3),
Adat5 = akció5(Adat4),
Sok hibalehetőséget rejt a változónevek szisztematikus és rutinszerű számozása. Az ilyen esetek sokkal egyszerűbb kezelése válna lehetővé, ha a paraméterek körbeadogatását valahogyan el tudnánk rejteni. Más esetekben az állapotot tartalmazó adatszerkezetet adogatjuk körbe-körbe az egész modulban, néha feleslegesen, néha változtatásokat beletéve, mivel – adatbázis használatán kívül – ez az egyetlen módja állapot számontartásának:
allapotgep1(Param1,Param2,Loopdata) -> valami,
Loopdata2= valtoztat(Loopdata),
allapotgep2(Param3,Loopdata2).
allapotget2(Param, Loopdata) ->
Param2 = Param + 3,
allapotgep3(Param2,Loopdata).
Sokkal szebb, átláthatóbb és kevesebb hibalehetőséget tartalmazó kódot eredményezne, ha megszabadulhatnánk az állapot (Loopdata) felesleges adogatásától. Ilyen esetekben sóvárogva gondol a funkcionális nyelvet használó programozó egy globális változó vonzó egyszerűségére. Jó lenne tehát tisztán funkcionálisan, de mégis elrejteni az állapot állandó jelenlétének terheit.
Monádok a Haskellben
A monádok Haskell-beli szerepét a mellékhatások és főleg a bevitel-kivitel (IO) kezelésében láthatjuk. A tiszta funkcionális programozás „fintora”, hogy egy egyszerű „Szia világ!” program Haskell-beli megírásakor máris a monádokba botlunk, ún. IO monádot kell használnunk:
main :: IO ()
main = putStrLn "Hello, World!"
Ennek oka, hogy a képernyőre kiírás mellékhatással jár, és a mellékhatás kiváltásának egyetlen módja a Haskellben, ha monádot használunk.
Megjegyzés: Hasonló problémák miatt – ui. semelyik funkcionális nyelven sem jellegzetes a kiíratást végző, egészen biztosan mellékhatásos kódrész – a funkcionális programozásban általában a faktoriális-számító program a legelső példa.
A monád konstrukció a Haskellben és a funkcionális programozásban alkalmas eszköznek mutatkozik tehát a mellékhatások kezelésére. A monádok jelentősége azonban nem csak ennyi. Tervezési mintaként általánosan is jól használhatók kombinátorok, konténerek ügyes megvalósítására.
Így nemcsak bevitel-kivitel, de állapotkezelés, kivételkezelés, többértékű számítások kezelése, „imperatív” tömb is megvalósítható monádokkal.
A monád mint a strukturálás eszköze
A Haskellben a monád tulajdonképpen egy adattípusból és a hozzá tartozó műveletekből álló konstrukció. Hogy általánosságban tudjunk beszélni róla: az adattípust általánosan a-val jelölve, az a adattípust tartalmazó monádtípust (Haskellben típusosztályt) M a-val jelöljük, pl. List-hez tartozó monád típusa M List.
A monádokat két nézőpontból is el lehet képzelni: egy monadikusan becsomagolt adat (Haskellben az M a típusosztály egy példánya) egyrészt lehet egy számítás, azaz egy lehetséges mellékhatás (M) és az adott típusú (a) érték együttese. Másképpen szemlélve M a egy konténer (doboz), ami egy (elrejtett) lehetséges plusz hatás (M) és egy érték (a) együttese. Az M-ről szóló rész mindig az, amit alig észrevehetően a kód mögé rejtünk a monadikus konstrukció segítségével. A monádokat ezért általánosságban konténerekként vagy számításokként képzeljük el. A monádokat alkalmazó programban ezen monadikus dobozokat csomagoljuk egy nagy monadikus dobozzá (számítássá) a monád csomagolásra vonatkozó praktikus tulajdonságait kihasználva.
A monádok népes és sokszínű családjába tartozó monád fajtákból íme egy kis gyűjtemény, az illető monád által modellezhető jelenségek feltüntetésével (a zárójelben a haskell monádtípus jelölése szerepel):
- lista-monád (M List): többértékű választásos számítások Olyan számításokat modellez, amelyek tetszőlegesen sok eredményt adhatnak, ezen eredményeket egy listában kapjuk vissza. Az is előfordulhat persze, hogy egy ilyen számítás nem ad eredményt, ekkor a [ ]-t adja vissza. Belsejében a listák kezelését rejti el.
- maybe-monád (M Maybe):
kétértékű választásos számítások Az előző esethez hasonló, ám a maybe-vel modellezhető számítások nem az eredmények számával, hanem a létezésével kapcsolatban határozatlanok: vagy adnak eredményt vagy nem. Ha a számításnak nincs eredménye, akkor nothing-ot kapunk vissza, ha van, azt az értéket valahogyan visszaadjuk. Belsejében az előző számítás eredményének vizsgálatát és annak létezésétől függő elágazást rejti el. - kivétel-kezelő monád (M Error):
számítások, amelyek hibát okozhatnak Az előző esethez hasonló, a számításnak vagy van eredménye, vagy hibát ad vissza. Belsejében szintén elágazást rejt, a hibákra történő – igen gyakori – vizsgálatokat. - állapot- monád (M State):
számítások, amelyek állapotot manipulálnak Valamilyen, tetszőleges szerkezetben tárolt belső állapot körbeadogatására. Belsejében egy lambda-függvény van, amely belül az állapotstruktúrát tartalmazza. Az ilyen elemek összekapcsolásakor az állapot a lambdákon keresztül végigfűződik a számításon. - Számozó monád (M Numbered, MNum):
számítások, amelyek egyedi számozást tesznek valamire Az előző speciális esete, ahol az állapotban a számlálót tároljuk, amelyet felhasználhatunk vagy inkrementálhatunk a használat során. Belsejében szintén lambda-függvény van. - „imperatív tömb”-monád (M Array, MA):
számítások, amelyek egy, az imperatív programnyelvek tömbjeihez hasonló tömböt manipulálnak Szintén az állapotkezelő monád speciális eseteként valósítható meg. Lehet számokkal indexelt, vagy akár asszociatív tömb is. - bevitel-kiviteli monád (M IO): kivitelt-bevitelt végrehajtó számítások Belsejében az IO-t modellező adatszerkezet (a kintről kapott karakterek és a kiírandó karakterek kifejezéseiből alkotott pár) van, hasonló az állapot-monádhoz, de az érték része gyakran üres (void).
A kategóriaelmélettől a funkcionális programozásig
Az Fp kategóriában az (F,?,µ) monád fölé épülő funkcionális programozásbeli monadikus
konstrukció a következő:
F egy funktor, amelynek FO része minden A adattípushoz egy FA adattípust rendel. (Mindez
csak az adattípusokra vonatkozik.) Emellett F funktor FM részét egy fmap magasabb rendű függvény valósítja meg, amely tetszőleges, A adattípuson operáló függvényre a neki megfelelő FA adattípuson operáló függvényt adja vissza.
?, azaz lift (elnevezési alternatívák: unit, return) egy leképzés, amely minden A adattípushoz
egy liftA függvényt rendel. Ez a liftA függvény az illető adattípus minden elemére FA adattípusba tartozó elemet ad vissza. Persze lehet, hogy lift nem több függvényt adó leképzés, egyszerűbb esetben csak egy, minden adattípusra működő függvény. A lift konkrét definíciója csak F ismeretében, az F-hez tartozó monád definíciójában adható meg.
bind függvény (operátor):
az FA adattípusba tartozó x elemre és egy A adattípusból FB
adattípusba képző f függvényre bind(x,f) egy FB adattípusba tartozó elemet ad vissza,
bind(x,f) = join (fmap f x)
ahol join ugyanezen monád kategóriaelméleti definíciójában meghatározott µ természetes transzformáció komponenseinek megfelelő magasabb rendű függvények összessége (join = µ). A bind definíciója az adott F-hez tartozó monád implementációjában adható csak meg programkóddal, ezen definícióban F pontos ismerete nélkül itt most nem lehetséges a bind konkrétabb megadása.
Megjegyzés: bind-ot most prefix függvényként definiáltuk, de lehetne infix is (úgy talán
kényelmesebb és jobban követhető lenne).
Az (F,lift,bind) hármas a funkcionális programban akkor és csak akkor monád, ha teljesülnek
az alábbi 3 monád törvény:
1. A programban szereplő minden A › FB típusú f függvényre:
bind(lift(x),f) = f(x).
2. Minden lehetséges FA típusú x-re:
bind(x, lift) = x
3. A programban szereplő minden f: A › FB, g: B › FC függvényre:
bind(bind(x,f),g) = bind(x, fun(y) -> bind(f(y),g))
(Megjegyzés: A lift , join és fmap tulajdonképpen polimorfikus függvények, azaz több adattípusra is működnek.)
Ez a monád definíció keretet ad konkrét F-ekhez, konkrét monádok készítéséhez. A monadikus konstrukció tehát mindössze az üres, absztrakt keret! Az egyes konkrét monád megvalósítások (lista-monád, állapotkezelő monád, IO-monád, maybe-monád stb.) töltik ki a keretben található üres részeket – F fogalmát, fmap, lift, join és bind definícióját. Az illető monád helyes használatához egy-egy konkrét lift és bind (ez a utóbbi tartalmazza joint és fmapot is) függvényre be kell látni vagy át kell gondolni a 3 monád törvény teljesülését.
Összefoglalva: A monadikus konstrukció és elméleti háttere, valamint Haskell és más nyelvekben betöltött szerepe a funkcionális programozás világának szerves része. A monád egy olyan konstrukció, amely kiegészíti a funkcionális eszköztárat, teret adva az imperatív jellegű konstrukciók megvalósításának. Ily módon a monádok olyan kérdésekre és hiányosságokra adnak választ, amelyek kulcsfontosságúak a funkcionális programozás gyakorlati alkalmazhatósága szempontjából, ugyanis ezen imperatív jellegű konstrukciók hiánya gyakori érv a funkcionális programozás gyakorlati alkalmazása ellen.
Funktorok
A három monadikus osztály közül talán a funktorok érhetők meg legkönnyebben. Ha valaki már használt funkcionális programnyelvet, bizonyára találkozott a listák map függvényével. Nézzünk a definíciót:
map :: (a->b) -> [a] -> [b]
map f [] = []
map f (x:xs) = (f x) +++ (map f xs)
A függvény az első paraméterében kapott függvényt elemenként alkalmazza a második paraméterében kapott listára, és az így kapott elemeket egyetlen listába fűzi össze. Például a listák elemeit duplázó függvényt valahogy így lehetne megírni:
dupl :: Int -> Int
dupl x = 2 * x
listdupl :: [Int] -> [Int]
listdupl = map dupl
-- Például:
listdupl [1,2,3] = [2,4,6]
A funktorokat egyfajta map függvények, amik nem feltétlenül listákkal dolgoznak, hanem más típusokkal is. Ha tetszik, a funktorok a map kiterjesztései, vagy méginkább: a map egy speciális funktor. A Functor osztály ugyanis egyetlen műveletet definiál, az fmap-ot, aminek nemcsak a neve hanem a típusa is nagyon hasonlít a fenti map-ra:
class Functor F where
fmap :: (a -> b) -> F a -> F b
Az osztálydefiníció azt mondja ki, hogy minden típus, amire implementáljuk az fmap műveletet a Functor osztályba tartozik. Listákra az osztály a következőképpen példányosítható:
instance Functor [] where
fmap = map
Az így definiált fmap teljesíti a következő feltételeket is:
fmap id = id
fmap (f.g) = fmap f . fmap g
Általában a polimorf típusokra gondolhatunk úgy, mint konténerekre, amik valamilyen egyéb információ mellett az alaptípusukba tartozó értékeket is tárolhatnak. A konténernek lehet valamilyen szerkezete is, például a lista egy lineáris polimorf típus, egy fa pedig lehet például bináris felépítésű. A fenti két feltétel annak matematikai megfogalmazása, hogy az fmap függvény a második paraméterében kapott konténer szerkezetén nem változtat, csak a benne tárolt értékeket változtatja meg (úgy, hogy alkalmazza rájuk az első paraméterében kapott függvényt). A szintaktikai megfelelésen túl a funktorokra ennek is teljesülnie kell, és mivel a listákra a dolog működik, a map függvény valójában nem más mint egy funktor.
Nézzünk meg bináris fákra is egy példát. Számunkra a fa elemei lehetnek levelek (Leaf) és ágak (Branch). Mindkettőben tárolunk valamilyen "a" alaptípusba tartozó értéket, és az ágaknak van két részfája is:
data Tree a = Leaf a | Branch a (Tree a) (Tree a)
Az ehhez tartozó funktor implementáció a következő:
instance Functor Tree where
fmap f (Leaf a) = Leaf (f a)
fmap f (Branch a l r) = Branch (f a) (fmap f l) (fmap f r)
Nézzünk meg egy egyszerű fán a listáknál már bemutatott duplázó függvény működését:
mytree = Branch 1 (Leaf 2) (Branch 3 (Leaf 4) (Leaf 5))
-- 1
-- |
-- +--+----+
-- | |
-- 2 3
-- |
-- +--+--+
-- | |
-- 4 5
treedupl = fmap dupl
treedupl mytree = Branch 2 (Leaf 4) (Branch 6 (Leaf 8) (Leaf 10))
-- 2
-- |
-- +--+----+
-- | |
-- 4 6
-- |
-- +--+--+
-- | |
-- 8 10
Figyeljük meg, hogy a fa szerkezete tényleg nem változott! A funktorok gyakorlati jelentősége abban rejlik, hogy segítségükkel az alaptípusokon definiált függvényeket "emelhetünk fel" a konténerek szintjére. Ezt a fogást gyakran használják funkcionális programok írásakor.
A monad osztaly
A monádok tulajdonképpen polimorf típusokból jönnek létre azáltal, hogy megvalósítjuk rájuk a Haskell Monad osztályának műveletit, az implementációnál ügyelni kell arra is, hogy a függvények megvalósítása megfeleljen a rájuk vonatkozó úgynevezett monadikus törvényeknek. Ennek a kategóriaelméleti háttér az oka (attól monád a monád, hogy ilyen és ilyen műveleti vannak ilyen és ilyen tulajdonságokkal). Sajnos a törvények betartását a rendszer nem képes ellenőrizni így az a programozóra marad, csakúgy mint például a funktoroknál említett tulajdonságok betartása és még sorolhatnánk.
A Monad osztály két alapművelete a >>= (bind) és a return, de a teljes definíció a következő:
infixl l >>, >>=
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
return :: a -> m a
fail :: String -> m a
m >> k = m >>= \_ -> k
Mivel a mondádok polimorf típusok, tekinthetők egyfajta konténernek is. A monádba mint konténerbe csomagolt értékeket monadikus értéknek nevezik. Az első két művelet, azaz a >>= és a >>, két monadikus értéket kombinál össsze. A return művelet pedig egy "a" típusú elemet helyez a monád konténerbe.
A bind művelet elsőre elég nehezen olvasható. Ez egy két paraméteres függvény: az első paramétere egy monád, a második pedig egy olyan függvény, ami a monádba csomagolt értékhez egy másik monádot rendel. A függvény eredménye szintén egy monád lesz. Tulajdonképpen arról van szó, hogy az első monádban tárolt érték alapján egy másik monádot állítunk elő.
A >> függvényt használjuk abban az esetben, ha a második monadikus érték meghatározása független az elsőtől. Látható, hogy ennek a műveletnek van egy alapértelmezett implementációja is, ami a >>= műveletet hívja úgy, hogy k-ból olyan függvényt készít, ami nem függ a paraméterétől.
Egy rövid példa bind műveletre a következő: a Haskellben az IO-t monádokon keresztül valósították meg. Az IO monádban az x >>= y az x és y IO művelet (getChar, putChar, stb.) egymás utáni végrehajtását jelenti úgy, hogy az y felhasználhatja az x eredményét. Például:
getChar >>= \a -> putChar a
A bind kiértékelése a következőképpen megy végbe: a getChar hívásakor a program vár egy billentyű lenyomására, majd ezt becsomagolja az IO konténerbe. Ezután a bind második argumentumának kiértékelése következik, ami kiveszi a beolvasott karaktert a konténerből és végrehajtja rá a \a -> putChar a függvényt, ami visszaírja a karaktert a képernyőre.
A bind és a return monadikus törvényei a következők:
return a >>= k = k a
m >>= return = m
xs >>= return . f = fmap f xs
m >>= (\x -> k x >>= h) = (m >>= k) >>= h
Az első kettőt identitásnak nevezik, az utolsót asszociativitásnak. A harmadik művelet a monadikus műveletek és funktorok közti kapcsolatot írja le.
Do-szintaxis
A fenti IO-s példa még viszonylag jól olvasható, de ennél sokkal szemléletesebben is meg lehetne írni a do szintaxis használatával. Ezt azért vezették be a Haskellbe, hogy egyszerűbbé tegyék a monádok használatát. (Később látni fogunk olyan példát, ahol a binddal összekapcsolt kifejezést alig lehet elolvasni, de do szintaxissal teljesen érthető.) Egy do kifejezés egyszerűen átírható monadikus műveletek alkalmazására:
do e1; e2 = e1 >> e2
do p <- e1; e2 = e1 >>= \p -> e2
Így a fenti példa a következő alakot ölti:
do a <- getChar; putChar a
A második esetben a p helyére nemcsak változót, hanem olyan kifejezést is írhatunk, amire az e1 művelet eredményének illeszkedni kell.
Például:
do 'c' <- getChar; putChar 'c'
Itt a felhasználónak a 'c' karaktert kell beütnie a billentyűzeten. Ha nem ez történik, a rendszer a fail függvényt hívja. A fenti átírás tehát nem volt teljesen pontos, precízen a következő:
do p <- e1; e2 = e1 >>= (\v -> case v of p -> e2; _ -> fail "s")
ahol "s" egy string, ami arról tájékoztat, hogy az e1 eredménye nem illeszkedik p-re. A fail is egyike a monád osztály műveleteinek, így ezt is a példányosító programozónak kell megírnia. Az IO például error hívással implementálja a failt-t, ami aztán terminálja a programot.
A MonadPlus osztály
A MonadPlus osztályt azok a monádok használják, amiknek van nullelemük és összegző műveletük:
class (Monad m) => MonadPlus m where
mzero :: m a
mplus :: m a -> m a -> m a
A nullelemre a következő szabályok vonatkoznak:
m >>= \x -> mzero = mzero
mzero >>= m = mzero
Az IO monádnak nincs nulleleme, így nem is tagja az osztálynak. Később bemutatjuk a lista monádot, aminek nulleleme az üres lista lesz. Az mplus-ra vonatkozó szabályok:
m 'mplus' mzero = m
mzero 'mplus' m = m
Az mplus művelet a hétköznapi konkatenáció a lista monádban.
Beépített monádok
Adottak a monadikus műveletek és a monadikus törvények. Felmerül a kérdés: mire használhatjuk ezeket? Először nézzük meg két beépített monád definícióját, majd egy összetettebb példában kitérünk az állapotmonádra (ez az IO alapja), és megvizsgáljuk hogyan szimulálhatunk erőforrás-kezelést Haskellben.
Listák
A listák bind műveletét úgy fordíthatnánk le, hogy a művelet baloldalán álló lista minden elemére végrehajtunk egy olyan függvényt, aminek az eredménye egy lista, végül ezeket konkatenáljuk egymással. Az osztály implementációja ebben az esetben:
instance Monad [] where
(>>=) :: [a] -> (a -> [b]) -> [b]
[] >>= f = []
(x:xs) >>= f = (f x) +++ (xs >>= f)
return :: a -> [a]
return c = [c]
Nézzünk egy egyszerű példát a működésre:
f :: Int -> [Int]
f a = [a+1]
Azaz az elemhez egyet adunk, és ebből egy egy elemű listát készítünk. Ekkor az [1,2,3] >>= f kifejezés értéke [2,3,4] lesz. A return művelet egy egyelemű listát készít az argumentumából, ezért f definícióját így is írhattuk volna:
f a = return (a+1)
Halmazkifejezések és monadikus műveletek
A do-szintaxis és a monádok kapcsolatát tovább bővíthetjük, ugyanis a Fraenkel-Zermelo halmazkifejezések is felírhatók do-szintaxissal, és így monadikus művetekkel is. Nézzünk egy egyszerű példát.
[(x,y) | x <- [1,2,3], y <- [1,2,3], x /=y]
A kifejezés értéke azon x,y párok listája, ahol x nem egyenlő y-nal és x is és y is eleme az {1,2,3} halmaznak, azaz:
[(1,2),(1,3),(2,1),(2,3),(3,1),(3,2)]
Ezt a következő alakban is írhatnánk, a Haskell do-szintaxisával:
do x <- [1,2,3]
y <- [1,2,3]
True <- return (x/=y)
return (x,y)
Amit gyakorlatilag ugyanúgy kell olvasni, mint az első alakot. x sorban felveszi a lista elemeit, miközben y is bejárja az {1,2,3} halmazt. Ha igaz, hogy x/=y, akkor a harmadik sorban illeszkedünk a True-ra és a végeredményhez hozzávesszük az (x, y) elemet. Egyébként a rendszer a failt-t hívja amit listák esetében egy üres lista visszaadásával implementáltak, az eredményhez ezt kell 'hozzáfűzni', majd egyszerűen vesszük a következő x, y párt.
Végül az egészet felírhatjuk bind műveletek segítségével, is:
[1,2,3] >>= (\x -> [1,2,3] >>= (\y -> return (x/=y) >>=
(\r -> case r of True -> return (x,y)
_ -> fail "")))
Ami valóban nehezen olvasható, de ebben az esetben nem ez a fontos, és különben is a do-t pontosan a szintaxis egyszerűsítésére vezették be. Az mindenesetre látható, hogy a definíció valóban függ a fail implementációjától.
A Maybe típus
A Maybe is a monád osztály tagja. Röviden azt lehet mondani, hogy [] helyett Nothing-et, [x] helyett pedig Just x-et kell írni, és a listás implementációból már meg is kaptuk a Maybe implementációját:
data Maybe a = Just a | Nothing
instance Monad Maybe where
(>>=) :: Maybe a -> (a -> Maybe b) -> Maybe b
Nothing >>= f = Nothing
Just a >>= f = Just (f a)
return :: a -> Maybe a
return c = Just c
Példák a monádok használatára A monadikus műveletek és törvények magyarázata nem igazán mutat rá a monádokban rejlő lehetőségekre. Az igazi erejük (erejük egy része) a modularitásban rejlik, ami alatt azt értjük, hogy ha egy-egy műveletet monadikusan definiálunk, akkor elrejthetjük az alatta húzódó kontsrukciót, és könnyen használható interfészt nyújthatunk a típus használóinak. Példáinkat a [2] cikkből vett állapot monáddal kezdjük, majd ennek mintájára definiálunk egy összetettebbet is.
Az állapot monád sokmindenre használható, például ezen alapszik több funkcionális nyelv IO kezelése. Mi egy egyszerű kalkulátor példájával kezdjük. A dolog lényege, hogy van egy S típusunk (az állapotok típusa), amit el akarunk rejteni a külvilág elől, ezért egy alkalmas monádot definiálunk köré. Ez a monád egyfajta állapotgépként fogható fel. Vannak típusműveletei, amikhez valamilyen számítási lépések kapcsolódnak, és a számítások során a háttérben a gép változtathatja az állapotát. Az állapot csak a típusműveleteken keresztül lehet hozzáférni és így mindenféle érdekes funkcionalitást nyújthatunk a felhasználónak. Például összeszámolhatjuk milyen műveletekből hányat hajtott végre, előállíthatjuk a végrehajtott műveletek listáját, vagy szabályozhatjuk, hogy melyik műveletet szabad végrehajtani, esetleg befolyásolni tudjuk a kiértékelés sorrendjét is. De térjünk is rá a definícióra:
data SM t = SM (S -> (t,S)) -- A monadikus típus
instance Monad SM where
-- a bind művelet továbbterjeszti az állapotot
SM c1 >>= fc2 = SM (\s0 -> let (r,s1) = c1 s0
SM c2 = fc2 r in
c2 s1)
return k = SM (\s -> (k,s))
-- az állapot kiolvasására
readSM :: SM S
readSM = SM (\s -> (s,s))
-- az állapot módosítására
updateSM :: (S->S) -> SM ()
updateSM f = SM (\s -> ((), f s))
-- egy kezdőállapotból indulva egy számítási sorozat végrehajtása
runSM :: S -> SM a -> (a, S)
runSM s0 (SM c) = c s0
A példa egy új adattípust definiál, SM-et. Az állapotgépünk egy konfigurációját egy (a,s) pár írja le, ahol a típusa tetszőleges, s típusa pedig S. (A példa egyelőre ezt sem rögzíti.) Ezzel elválasztottuk a felhasználói részt (első komponens) a gép belső állapotától (második komponens). SM-elemei számítások, egy kezdőállapotból valamilyen végállapotba vezetnek, miközben a felhasználói komponensbe egy eredményt állítanak elő.
A számítások nagyon sokfélék lehetnek, de kitüntetjük közülük a return művelet eredményeként létrejötteket. Ezek a gép belső állapotán nem változtatnak, csak visszaadják eredményül a return paraméterét (a definícióban ezt k jelöli). Azért lesznek nagyon fontosak, mert a felhasználó ezen keresztül adhat induló paramétereket a gépnek.
Számítások egymással a bind művelet segítségével kombinálhatók, így hosszú láncok alakulhatnak ki, a definíciónak köszönhetően ezek kiértékelése csak szekvenciálisan hajtható végre: a láncban később álló tagok a megelőző tagok eredményétől függenek. A definíció ezt lambdakifejezésel írja le, de a megértés talán egyszerűbb ha a következő (ekvivalens) alakot nézzük:
(SM c1 >>= fc2) s0 = let (r,s1) = c1 s0
SM c2 = fc2 r in
c2 s1
Semmi más nem történt, csak a definícióban szereplő s0-t (a lambdakifejezés paraméterét) átírtuk az egyenlőség baloldalára. Ezzel a függvényt nem 'önmagában', hanem elemenként definiáljuk. Röviden arról van szó, hogy az SM c1 számítás után szeretnénk végrehajtani valamit ami felhasználhatja az előző eredményét. Az s0 kezdőállapotból c1 (r, s1)-be vezet. fc2 r-rel meghatározzuk a következő végrehajtandó számítást, ez SM c2 lesz, végül az eredményt úgy kapjuk, hogy megnézzük hová jutunk c2-vel s1-ből.
Az alap monadikus műveletek mellett definiáltunk néhány monadikus primitívet is. Egy monadikus primitív egyszerűen egy művelet, ami ismeri a definiált monád szerkezetét, és a belső implementációt elfedve valamilyen funkcionalitást nyújt a felhasználónak. Például az IO monád operátorai (putChar, getChar), is ilyen primitívek, hiszen az IO monád belső reprezentációjára építenek. Hasonlóan a mi állapot monádunknak is van két primitíve: a readSM és az updateSM.
A readSM-et használhatjuk arra, hogy a pillanatnyi állapot megfigyeljük, hiszen a függvény az állapoton nem változtat, és értéke pontosan ez az állapot lesz. Ez jól jöhet abban az esetben, ha a gép állapota alapján akarunk dönteni a következő számítási lépésről. Az updateSM-et az állapot módosítására használhatjuk.
Végül szükségünk van egy függvényre, ami egy számítást futtat a gépen. Erre szolgál a runSM. Paramétere a kezdőállapot és egy számítás, eredménye a számítás értéke a kezdőállapotból indulva, és a végállapot.
Összefoglalva az eddigieket látható, hogy egy tetszőleges számítást elemi lépések sorozataként kezelünk (különböző SM t típusú függvényekkel), amiket a >>= operátorral kapcsolunk össze. A return műveletet használjuk arra, hogy különböző értékeket emeljünk be a világunkba. Az elemi lépések kapcsolódhatnak a rendszer állapotához, lekérdezhetik, módosíthatják (readSM, updateSM), vagy egyszerűen figyelmen kívül hagyhatják. Ugyanakkor az állapot használata (vagy nem használata) rejtve marad: akár használják a lépések az állapotot akár nem, ugyanúgy hajtjuk végre és kapcsoljuk össze őket.
Példa: egyszerű kalkulátorA következőkben egy egyszerű példát mutatunk a fenti monád alkalmazására. Definiáljuk a kifejezések típusát, majd egy egyszerű "számológéppel" a típusértékekhez megadjuk az általuk reprezentát számot:
data Expr = Con Integer| Div Expr Expr
Tehát egy kifejezés lehet egész, vagy két kifejezés hányadosa. A példa természetesen nagyon leegyszerűsített, aminek az oka, hogy nem akarjuk elfedni a dolgok lényegét.
A típushoz tartozó "számológép" a következő lehetne:
eval :: Expr -> Integer
eval (Con a) = a
eval (Div t u) = div (eval t) (eval u)
A definíció nem szorul különösebb magyarázatra. A div egészosztást végez a két paramétere között. Nézzünk egy példát a működésre:
answer = (Div (Div (Con 1972) (Con 2)) (Con 23))
eval answer => 42
Több kérdésünk is lehet, például mi van a nullával való osztással, hány osztást kell végezni az eredmény meghatározásához., vagy: határozzuk meg a kiértékelés során elvégzett műveleteket, és ezeket írassuk ki a képernyőre. Wadler cikke mindháromra mutat elegáns megoldást a monádok segítségével. Mi itt a másodikat tárgyaljuk.
Ha belegondolunk, a kérdés megválaszolásához teljesen át kellene alakítani a megoldást, mert a Haskell nem ad lehetőséget változók használatára (amivel hamar megoldhatnánk a problémát egy imperatív nyelvben). Viszont az állapot monád segítségével, ha sikerül a kifejezések kiértékelését elemi számítások sorozatára bontani, akkor a rendszer állapotában (az S-ben) tárolhatjuk az osztások számát is. Ehhez először is szükségünk lesz a monádra:
data SM a = SM (S -> (a, S))
type S = Integer
Az állapotban most egészeket tárolunk. Nézzük milyen eval függvényt írhatunk ehhez a megoldáshoz:
evalSM :: Expr -> SM Integer
evalSM (Con a) = return a
evalSM (Div t u) = do a <- evalSM t
b <- evalSM u
updateSM inc
return (div a b)
inc :: S -> S
inc s = s + 1
Látható, hogy a Con a kiértékelése egyenértékű egy return művelettel, tehát "a"-t becsomagoljuk egy (a,s) párba - pontosabban egy olyan számításba, ami egy adott s állapotra az (a,s) párt eredményezi. A Div esetében egy kicsit több dolgunk van. Először meghatározzuk a t értékét, ez egy (a, s') pár, de ebből a do-ban csak a pár első tagját kapjuk vissza (a felhasználó részt). Aztán meghatározzuk u értékét is, az inc függvénnyel eggyel növeljük a világunk belső állapotának értékét (hiszen most egy osztás következik), végül elvégezzük az osztást. A do-szintaxinak köszönhető, hogy az állapotkomponenst el tudtuk rejteni a felhasználó elől, nem is kell tudnia róla, hiszen csak a monadikus primitíveken keresztül akarjuk engedélyezni a hozzáférést. A bind művelet trükkös implementációjának köszönhető, hogy bár az állapot komponens a definícióban ki sincs írva, a kulisszák mögött mégis átadódik és az updateSM függvény végrehajtásakor egyel növekszik is az értéke.
Erőforrások
Nézzünk meg egy összetettebb példát is. Definiálunk egy kis nyelvet a Haskellen belül, amivel "erőforrás-igényes" számításokat végezhetünk: megadhatunk egy kezdeti erőforrást, amivel a számításaink gazdálkodhatnak. Ha van szabad erőforrásunk, akkor a számítás egy lépését végrehajthatjuk, ha nincs, akkor a kiértékelést felfüggesztjük. Definiáljuk R típust a következőképpen:
data R a = R (Resource -> (Resource, Either a (R a)))
Minden számítás egy függvény lesz, ami egy erőforráshoz egy újabb erőforrást és vagy egy eredményt (a), vagy egy felfüggesztett számítást (R a) rendel.
Az Either típus definíciója:
data Either a b = Left a | Right b
Lássuk a monadikus műveletek implementációját:
instance Monad R where
R c1 >>= fc2 = R (\r -> case c1 r of
(r', Left v) -> let R c2 = fc2 v in
c2 r'
(r',Right pc1) -> (r',Right(pc1 >>= fc2)))
return v = R (\r -> (r, (Left v)))
A Resource típust ugyanúgy használjuk, mint az állapot monád állapotát. A definíciót a következőképpen olvashatjuk: két "erőforrás-igényes" számítás eredményét úgy kapjuk meg, hogy először elvégezzük az első számítást (c1) a rendelkezésre álló erőforrásokkal (r). Ha az eredmény nem egy felfüggesztett számítás (azaz Left v), akkor ez alapján fc2-vel meghatározzuk a következő számítást (c2), és végrehajtjuk a maradék erőforrásokkal (r'). Ha c1 végrehajtásakor felfüggesztett számítást kapunk eredményül (Right pc1), akkor nincs mit tenni: az eredmény egy felfüggesztett számítás lesz, amit nem sikerült végrehajtani (pc1) és amit ezután kellett volna végrehajtani (fc2), azaz Right( pc1 >>= fc2). A return definíciója most is egyszerű, egy értéket csomagol be egy olyan számításba, aminek eredménye ez az érték, az erőforrásokat pedig, változatlanul hagyja.
Példa az erőforrásokra
A fenti példányosítás csak a monád alapstruktúráját határozza meg, de nem mond semmit az erőforrásokról. Ez a monád sokféle erőforrással elboldogul, és többféle erőforrás-használati stratégiát is definiálhatunk, itt csak egy nagyon egyszerű esetet mutatunk példaként. Legyen az erőforrások típusa Integer, a még rendelkezése álló lépések számának tárolására.
type Resource = Integer
A következő függvény egy lépést tesz, ha még van szabad erőforrásunk.
step :: a -> R a
step v r = if r/=0 then (r-1, Left v)
else (r, Right (step v))
A függvényt használhatjuk arra is, hogy felemésszük az erőforrásainkat, csak elég sokszor kell önmagával összekötni >>= operátorokkal, de sokkal hasznosabb, ha más függvényeket definiálunk segítségével:
incR :: R Integer -> R Integer
incR i = do iValue <- i
step (iValue + 1)
Az incR a becsomagolt Integer-t növeli eggyel. A <- ahhoz kell, hogy a monádból kivegyük ezt az értéket (iValue típusa Integer, nem R Integer), majd egy lépésben megnöveljük az értékét, és visszacsomagoljuk a monádba.
A definíció nem elég világosan olvasható. Sokkal jobb lenne, ha a megszokott operátorainkat, mint például a +, használhatnánk. Ehhez néhány olyan függvényt kell bevezetnünk, amik már létező műveleteket emelnek monadikus szintre. Vegyük például a következőt:
lift1 :: (a -> b) -> (R a -> R b)
lift1 f = \ra1 -> do a1 <- ra1
step (f a1)
Ez egy egyváltozós függvényt kap argumentumként, amiből egy olyan függvényt készít, ami R-ben hajtja végre f-et egy lépésben. Ezt felhasználva incR-re a következő adódik:
incR :: R Integer -> R Integer
incR = lift1 inc
Vezessük be a következőt:
lift2 :: (a->b->c) -> (R a -> R b -> R c)
lift2 f = \ra1 ra2 -> do a1 <- ra1
a2 <- ra2
step (f a1 a2)
Vegyük észre, hogy a függvény meghatározza az argumentumainak kiértékelési sorrendjét: az a1-et eredményező számítás az a2-t eredményező előtt fut le.
A lift2-vel definiálhatunk egy új egyenlőséget az R monádban:
(==*) :: Ord a => R a -> R a -> R Bool
(==*) = lift2 (==)
Sajnos nem használhatjuk az ==-t, mert annak az eredménye kötelezően Bool típusú, nem R Bool. A következő példányosítás lehetővé teszi a szokásos aritmetikai műveletek használatát R-ben:
instance Num a => Num (R a) where
(+) = lift2 (+)
(-) = lift2 (-)
negate = lift1 negate
(*) = lift2 (*)
abs = lift1 abs
fromInteger = return . fromInteger
Mivel a fromInteger függvény automatikusan végrehajtódik az egész konstansokra a fenti definíció lehetővé teszi, hogy ez egészekre R Integerként tekintsen a Haskell. Így az incR függvény végül a következő egyszerű formát ölti:
incR :: R Integer -> R Integer
incR x = x + 1
Ha érdekesebb számításokat is szeretnénk definiálni (márpedig szeretnénk), akkor szükségünk lesz elágazásokra. Sajnos az if-et nem használhatjuk, mivel a feltétele Bool típusú, de vegyük helyette az ifR-t:
ifR :: R Bool -> R a -> R a -> R a
ifR tst thn els = do t <- tst
if t then thn else els
Most nézzünk egy bonyolultabb programot a monádban:
fact :: R Integer -> R Integer
fact x = ifR (x ==* 0) 1 (x * fact (x-1) )
Ami nem pontosan ugyanúgy néz ki, mint a hétköznapi faktoriális függvény, de egész olvasható. Az ötlet, hogy új definíciókat vezetünk be a meglévő műveletekre, mint a + vagy az if, alapvető beágyazott nyelvek definiálásakor. A monádok nagyon jól használhatók az ilyen beágyazott nyelvek szemantikájának egységbezárására.
Nézzük, hogyan futtathatunk egy programot a monádban:
run :: Resource -> R a -> Maybe a
run s (R p) = case (p s) of
(_, Left v) -> Just v
_ -> Nothing
A függvény a rendelkezésre álló erőforrásokkal (s) végrehajtja a műveletsorozatot (p). Az eredményben a Maybe típust használjuk az esetlegesen felfüggesztett számítások kezelésére. Az eredmény így Just v vagy Nothing aszerint, hogy volt-e elég erőforrás a számítások elvégzésére. Néhány példa a használatra:
run 10 (fact 2) => Just 2
run 10 (fact 20) => Nothing
Végül adjunk egy érdekes funkcionalitást a monádunkhoz:
(|||) :: R a -> R a -> R a
c1 ||| c2 = oneStep c1 (\c1' -> c2 ||| c1')
where
oneStep :: R a -> (R a -> R a) -> R a
oneStep (R c1) f = R (\r -> case c1 1 of
(r', Left v) -> (r+r'-1, Left v)
(r', Right c1') -> -- r' must be 0
let R next = f c1' in
next (r+r'-1))
A (|||) függvény két számítást futtat párhuzamosan. Eredménye annak a számításnak az értéke, amelyik hamarabb befejeződik. Vizsgáljuk meg a definíciót közelebbről. A függvény a oneStep lokálisan definiált függvényt hívja. Ennek első argumentuma egy számítás, második argumentuma pedig egy függvény, ami azt írja le, hogy mi a teendő, ha az első argumentumot nem lehetett egy lépésben kiértékelni. A függvény tehát úgy működik, hogy egy lépést végrehajt az első paraméteréből (ezt írja le a c1 1 kódrészlet), majd ennek eredményétől függően visszaadja az eredményt és az erőforrások számát eggyel csökkenti (az r+r'-1 ennek trükkös megfogalmazása). Abban az esetben, ha a számítást nem lehetett egy lépésben meghatározni, a kapott eredményre alkalmazni kell a oneStep függvény második argumentumát. Ez azt a next-ben tárolt számítást adja, amivel a végrehajtást folytatni kell. Mivel a ||| definíciójában a oneStep második paramétere egy olyan függvény, aminek eredménye a ||| második paraméteréből (c2) és a már részben kiértékelt elsőből (c1') álló párhuzamos számítás, a feldolgozás a második számítással fog folytatódni, de már eggyel kevesebb erőforrással. A folyamat így folytatódik váltakozva, amíg valamelyik számítást teljesen ki nem lehet értékelni (vagy végleg el nem fogynak az erőforrások).
Most kiszámíthatunk olyan kifejezéseket, mint run 100 (fact (-1) ||| (fact 3)), az eredmény 6 lesz (pontosabban Just 6), hiszen a fact (-1) számítása végtelen ciklust eredményez, tehát csak a 3!-t tudjuk meghatározni.
Sok lehetőségünk van a struktúra bővítésére. Például az erőforrások mellé bevehetnénk egy másik állapotkomponenst, amiben a kiértékelés nyomát tárolnánk. Vagy beágyazhatnánk a monádot a standard IO monádba, hogy kommunikálhasson a külvilággal....
Példa:
i : INTEGER; -- expanded típus
s1 : ARRAYED_STACK[REAL]; -- az ARRAYED_STACK referencia osztály, ezért ez referencia
s2 : expanded ARRAYED_STACK[REAL]; -- ez most egy ARRAYED_STACK objektum lesz
- A Pascal nyelvhez hasonlóan az egész és valós osztás operátora nem ugyanaz. (Az egész osztás operátora a //, a valósé pedig a /). Így elkerülhetőek az abból származó meglepetések, hogy a programozó két egész számra véletlenül egész osztást alkalmaz amikor valósat szeretett volna.
- A aritmetikai típusokra definiált a hatványozás operátor ("^"). Ez két egész szám esetén is valós eredményt ad a túlcsordulások elkerülése céljából. (Például 100^100 már nem ábrázolható 32 biten.).
- Logikai kifejezésekben a szokásos "or", "and" és "not" operátorok mellett alkalmazható az "xor" (kizáró vagy) és az "implies" (implikáció) operátor is. Az "and" és "or" operátorok esetén nem garantált a lusta kiértékelés. Ha erre van szükség, akkor az "and then" és "or else" operátorokat kell használni, ugyanúgy, mint Adában.