
Az alábbi fordítást Petheő Á. Balázs készítette. Az eredeti megtalálható ftp://ftp.geoinfo.tuwien.ac.at/navratil/HaskellTutorial.pdf.
Segédlet a Haskell programozási nyelvhez
Damir Medak és Gehard Navratil
Bécsi Műszaki Egyetem, Geoinformatikai Intézet
2003. február
Számtalan könyv szól a funkcionális programozásról. Jók ezek a könyvek, bár általában arra tesznek kísérletet, hogy megtanítsanak a diákoknak mindent, amit az szerzők maguk valaha is megtanultak az adott témával kapcsolatban.
Ezért az olvasó már a legelején összezavarodik: a rázúduló információ mennyiségétől, vagy éppen az elméleti anyag konkrét, hasznos alkalmazási példáinak hiányától. Általában az olvasó hamar ki szeretné próbálni az elvont koncepciókat, de ötlete sincs, hogyan fogjon hozzá.
Mi a következőkben a funkcionális nyelvek alapjait szeretnénk kifejteni kezdők számára. Célunk, hogy képessé tegyük az olvasót konkrét programkód írására, ami majd a későbbiekben felkelti az érdeklődését az elméleti háttér iránt is. Az alapvető matematikai ismeretek meglétét feltételeztük.
Meg kell jegyeznünk mindemellett, hogy két olyan aspektust nem vettünk figyelembe, amelyek fontosak lehetnek néhány olvasó számára:
- Nem törődünk a hatékonysággal! Egyszerűen csak függvényeket specifikálunk és modelleket alkotunk. Nem gyors vagy hatalmas szoftverekre, hanem egyszerűen megérthető modellekre koncentrálunk.
- Nem definiálunk felhasználói interfészt. Nem foglalkozunk a felhasználóval vagy más programokkal, fájlokkal való interakciókkal. A nyelvet csak modellezésre használjuk, a tesztelés pedig parancssorban történik.
1. Előfeltételek
Érdemes a számítógép előtt ülve olvasni ezt a segédletet és a példákat azonnal ki is próbálni. Ezért ajánlott installálni a Hugs (98)-at és egy megfelelő szerkesztőt (pl. UltraEdit).
1.1 A Hugs installálása
Egy programozási nyelvről olvasni unalmas, ha az olvasó nem kísérletezhet közben vele. A Haskell esetében erre megoldás a Hugs (Haskell User's Gofer System). A legfrissebb verzió megtalálható az Interneten: www.haskell.org
Jelen pillanatban az utolsó verzió 2002. novemberi (2003. februárjában). Elérhető verzió Windows-hoz, Unix-hoz, Linux-hoz, MacOS X és MacOS 9 alá is. Mi a windows-os verzióra utalunk, ha a felhasználói interfészről beszélünk. A többi operációs rendszerhez érdemes elolvasni a dokumentációt. A Windows alatt használható fájl egy "Windows telepítő csomag" (msi), a telepítés rögtön a duplaklikk után kezdődik. Ajánlott elolvasni a súgó fájlt a hibák elkerülése, valamint kiegészítő információk megszerzése végett.
- Futtasd a telepítő programot.
- Ellenőrizd, hogy van-e szerkesztő programod installálva. Ha nincsen, telepíts azt is.
- Ha UltraEdit-et használsz, állítsd a szerkesztő opciót a Hugs-ban UEdit32 %s/ %d/ 1 - re. Ha más editort használsz, akkor az "UEdit32" helyére a választott szerkesztőd nevét írd, a paramétereket helyére pedig azokat a paramétereket írd, amelyek az adott editorban a fájl megnyitásához kellenek, illetve ahhoz, hogy a szövegben egy meghatározott sorra ugorjon.
| DOS-verzió | Windows-verzió | |
|---|---|---|
| Parancssor | dir \HUGS.EXE %F | dir \WINHUGS.EXE %F |
| Munkakönyvtár | %P | %P |
| Windows program? | Nem Ellenőrzött | Ellenőrzött |
1. táblázat: Fontosabb parancsokat, hogy a Hugs-t eszközként az UltraEdit-hez adhassuk
Az 1. táblázat megadja a fontosabb parancsokat ahhoz, hogy a Hugs-t eszközként az UltraEdit-hez lehessen adni. A dir szó helyére a parancssorban azt a könyvtárat kell írni ahová a Hugs telepítve lett.
1.2 Mit tanít meg nekünk ez a segédlet?
Ez a segédlet egy nehéz utat mutat a funkcionális programozás elsajátításához, mert könnyen nem lehet semmi hasznosat sem tanulni. (Ha jobban szereted a formális metódusokat, fogj egy tetszőleges könyvet az elsőrendű logikáról, olvass el egy vagy két fejezetet, és biztosan vissza fogsz hozzánk térni.)
Könnyű feladatok fognak megismertetni téged a Hugs-szal (megjegyzéseket és javaslatokat szívesen veszünk!). Olyan egyszerű leckékkel fogunk kezdeni, mint pl. a függvények definiálása, adattípusok, majd továbblépünk a bonyolultabb eljárásokra, az objektumorientált programozásra és a modularizálásra.
2. Alapvető típusok, avagy "Hogyan kell a Haskell-t működésre bírni"
Próbáld ki a következő függvényeket a Hugs-ban - mentsd el őket egy fájlba, töltsd be a Hugs-ban és teszteld őket!
2.1 Írasd ki, hogy "Hello world" a parancssorban
Nem nagy dolog, minden nyelv meg tudja tenni; Haskell-ben a putStr művelettel lehet egy sztringet a képernyőre kiírni. Nyisd meg a Hugs-t és írd a következőket a parancssorba [1]:
putStr "Hello"
Az eredménynek így kellene kinéznie:
Hello
(2 reductions, 7 cells)
?
Az első sor a parancs eredménye. A második sor a parancs kiértékeléséről ad némi infomációt. Az interpreter a függvényeket egyszerűbb függvényekkel helyettesíti mindaddig, amíg minden rész egy egyszerű direkt implementációs lépésre nem redukálódik (hasonlóan más interpretált nyelvekhez, mint például az eredeti Basic). Ezeket a helyettesítéseket redukcióknak hívják. A "cellák" (cells) értéke az a memóriamennyiség, ami a redukciók elvégzéséhez és az eredmény kiíratásához kell.
Nyisd meg az editort (a parancssorba gépeld be, hogy ':e') és írd be ugyanezt a parancsot a szerkesztő ablakba (használd a 'new file' és 'save file as' editor-parancsokat). Függvényként írjuk meg, azaz adunk neki nevet (jelen esetben f) és azt elválasztjuk a függvénydefiníciótól az '=' karakterrel. Mentsd el a fájlt '.hs' kiterjesztéssel.
f = putStr "Hello"
Töltsd be a fájlt a Hugs-ban[2] és futtasd a függvényt. Függvényt futtatni a Hugs-ban igazán egyszerű. Csak be kell gépelned a parancssorba a függvény nevét (itt: f) és a paramétereket (ebben az esetben nincsenek). Az eredmény:
? f
Hello
(3 reductions, 15 cells)
?
Az előző megoldással szemben itt a redukciók száma 3 (2 helyett) és a felhasznált cellák száma 15 (7 helyett). A redukciók száma azért nőtt meg, mert az interpreternek az f-et helyettesítenie kell a putStr "Hello"-val. Ez egy plusz redukciós lépés, ami némi memóriát is követel.
2.2 Függvényírás Haskell-ben
Egy funkcionális nyelvben minden függvény (még a program is). Így a programírás tulajdonképpen függvényírás. Egyetlen fájlba több függvényt is írhatsz, azaz több programod is lehet egy fájlban. Minden függvény használhatja a többi függvényt az eredmény számításához. Mint ahogyan az már más nyelveknél megszokott, sok előredefiniált függvény van. Ezeket a függvényeket tartalmazó fájlok a 'hugs98\lib' könyvtárban találhatók.
A függvényírás két részből áll. Először definiálnunk kell az argumentumok és az eredmény típusát. Lehet, hogy egy függvénynek nincs argumentuma, ekkor konstans függvénynek hívjuk. Ilyen függvényre példa a pi függvény, ami a π értékét adja vissza, amihez nyílván nincs szükség argumentumokra. Más függvényeknek lehet 1 vagy több argumentuma is. Eredménye viszont minden egyes függvénynek van, pontosan 1 darab, pl.:
increment:: Int -> Int
Új függvényünk neve increment. A '::' jel választja el a függvény nevét a típusdefiníció(k)tól. Ha több, mint egy típust használunk, akkor a típusokat a -> jel választja el. Az utolsó típus a listában mindig az eredmény típusa[3].
A függvényírás második szakasza a konkrét implementáció, pl.:
increment x = x + 1
Az increment függvénynek van egy Int (egész szám) típusú argumentuma és Int-tel is tér vissza. Hogy teszteljük a működését, gépeljük be a Hugs-prompt után, hogy "increment 2" (az idézőjelek nélkül), az eredmény valami ilyesmi lesz:
3 :: Int
Ha a Hugs a 3-at típus nélkül írná ki, akkor az "Options/Set..." menüpontban ellenőrizd le, hogy a "show type after evaluation" be van-e kapcsolva. Ha nincs, akkor az interpreter csak az eredményt írja ki anélkül, hogy megadná annak típusát.
Nézzünk egy másik példát. Más programozási nyelvekhez hasonlóan a Haskall-ben is van egy előredefiniált adattípus Boolean értékekhez. A Boolean értékek egyik fontos művelete a logikai és. Bár a Haskell-ben van ennek megoldására függvény, írjuk meg mi is. Egy megoldás lehet a következő:
and1 :: Bool -> Bool -> Bool
and1 a b = if a == b then a
else False
Itt egy elágazást használunk (if-then-else) az eredmény kiszámolási eljárásának felosztására. Ha a paraméterek egyenlőek (mindkettő True vagy mindkettő False), akkor a paraméterek egyikének az értékével térünk vissza. Ha a paraméterek nem egyenlőek, akkor False-t adunk vissza. Egy másik megoldásként mintaillesztést is használhatunk. a logikai és-nek csak egy esetben lesz az eredménye True, minden más esetben az eredmény False. Tudjuk, hogy milyen paraméterek felelnek meg annak az egy esetnek. Ezeket a paramétereket egy külön sorba írhatjuk, ahol megadhatjuk a végeredményt is. A többi esetre írunk egy második sort:
and2 :: Bool -> Bool -> Bool
and2 True True = True
and2 x y = False
Ebben a példában a második sorban nem használtuk a paramétereket az eredmény kiszámításakor. Nem szükséges ismerni a paraméterek értékeit, mert az eredményünk ebben az esetben úgyis konstans. A Haskell-ben '_'-t is írhatunk az ilyen paraméterek nevei helyett. Ez a jelölés előnyös a program olvasója számára, mert tudja belőle, hogy hány paraméter van, de azt is, hogy az eredmény független ezeknek a paramétereknek az értékeitől. Tehát a második sor kinézhet így is:
and2 _ _ = False
2.3 A másodfokú egyenlet gyökeinek kiszámítása (a where és az if then else gyakorlása)
A függvényírás első lépése a megoldandó probléma definiálása. Definiálnunk kell a megoldás szignatúráját.
Először is ne felejtsd el, hogy a függvény, amit írsz, tulajdonképpen egy program - készíts vázlatokat, írj megjegyzéseket, jegyzeteket, valamint korábban megoldott feladatokat is használj fel programozás közben. Nem a gépelés öröméért - ez munkastílus.
A másodfokú egyenletek a következőképpen néznek ki: ax^2 + bx + c = 0. Az egyenletnek két gyöke van (vagy egy, ha a gyökök egybeesnek). A matematikai megoldás a következőképpen néz ki:

A gyököket kiszámoló függvénynek egy értékhármas a bemenete és egy értékpár a kimenete. Ha a Float típust használjuk, a definíció Haskell-ben így néz ki:
roots :: (Float, Float, Float) -> (Float, Float)
A függvény neve roots. A '::' jel szeparálja a függvény nevét a típusdefinícióktól. A '->' jel választja el a különböző típusdefiníciókat. Az utolsó a függvény eredményének (kimenet) típusát definiálja, a többi paraméter (bemenet). Tehát a (Float, Float, Float) a függvényünk paraméterének típusát definiálja, melyet három Float értékkel reprezentálunk. A függvény eredménye (Float, Float), azaz egy Float értékekből álló pár.
A következő lépés a roots függvény definiálása:
roots (a,b,c) = (x1, x2) where
x1 = e + sqrt d / (2 * a)
x2 = e - sqrt d / (2 * a)
d= b * b - 4 * a * c
e= - b / (2 * a)
A függvény eredménye az (x1,x2) pár. Mind x1 és x2 lokálisan van definiálva (a where klóz után). A lokális definíciók az eredmény részszámolását végzik. Általában hasznos a lokális definíciók alkalmazása részszámításoknál, ha azok eredménye egynél többször lesz felhasználva. Az e és d lokális definíciók eredményei például a végleges eredmény mindkét részéhez (x1 és x2 ) kellenek. A megoldásokat egyenesen az eredményhármasba írhatnánk, de a lokális definiálás megnöveli az olvashatóságát a kódnak, mert a megoldás szimmetriája tisztán látható.
A felhasznált formulák a másodfokú egyenletek jól ismert megoldóképletéből valók.
Bár ez a függvény működik, de nem figyel oda az esetleges negatív gyökökre. Ezt könnyen le is tesztelhetjük:
p1, p2 ::(Float, Float, Float)
p1 = (1.0, 2.0, 1.0)
p2 = (1.0, 1.0, 1.0)
p1-re az eredmény:
? roots p1 (-1>.0,-1.0) :: (Float,Float)
(94 reductions, 159 cells)
Viszont p2-re a következő adódik:
? roots p2
( Program error: {primSqrtFloat (-3.0)}
(61 reductions ,183 cells)
A Program error: megjegyzés egy futásidőbeli hibát mutat. A zárójel a fenti szövegben azért látható, mert a Haskell már elkezdte kiírni az eredményt, amikor a hiba bekövetkezett. A zárójel a megoldás-pár kezdete. A hibajelzés utáni szöveg pontosan megmondja a hibát. Jelen esetben a szöveg azt mondja, a primSqrtFloat függvény nem tudja kezelni a -3.0 paramétert, amely negatív, így nincs valós gyöke. A primSqrtFloat függvény az sqrt függvény implementációja Float típusra.
Változtatnunk kell a programkódon, hogy tudja kezelni az olyan kivételeket, mint például a nem valós gyökök felbukkanása:
roots (a,b,c) = if d < 0 then error "sorry" else (x1, x2)
where x1 = e + sqrt d / (2 * a)
x2 = e - sqrt d / (2 * a)
d = b * b - 4 * a * c
e = - b / (2 *a)
A függvény most már teszteli a d lokális definícióban kapott értékét és ha d negatív, akkor kiír egy a felhasználó által megadott hibaüzenetet. Ha ez a hiba nem lép fel, akkor a függvény a korábbiakkal azonos módon kiszámolja az egyenlet gyökeit.
Magyarázatok erre a megoldásra:- Az if-then-else konstrukció a következőképpen működik: "ha a feltétel teljesül (True), akkor végezd el az első műveletet (a then után), inden más esetben a második műveletet végezd el (az else után)".
- A where az előző sorhoz tartozik, mert beljebb van kezdve, valamint a következő négy sort egyformán beljebb kell kezdeni, mert azok egy szinthez tartoznak.
- Hogyan lehetséges gyököt vonni d-ből az x1-es sorban, ha d < 0.0 ? A válasz az, hogy a gyök ebben az esetben soha nem lesz kiszámítva, mert a funkcionális programok csak azokat a kifejezéseket értékelik ki, amelyek értéke éppen nélkülözhetetlen az eredmény előállításához.
- Amikor a programnak szüksége van d-re, akkor kiszámolja és ha az értéke negatív, akkor hibaüzenetet ad, majd befejezi a futást.
- Ha d nem negatív, akkor a program kiszámolja 1-et. Ezután szüksége lesz e-re, kiszámolja, abból kiszámolja x2-t majd befejezi a futást.
A függvények viselkedését tesztelni kell. Ha az interpreter nem ír ki hibaüzenetet, akkor a függvényünk megfelelt minden szintaktikai szabálynak (pl.: minden nyitó zárójelnek van záró párja). Ha olyan hibaüzenetet kapunk a függvény betöltése vagy futtatása közben, amely tartalmazza a typ szót, akkor biztosan a típusstruktúrával van gond, pl.: a szignatúrában specifikáltaknak nem felel meg, stb. A szintaktikailag már helyes függvénynek szemantikailag is helyesnek kell lennie: könnyen lehet, hogy rossz eredményt kapunk, vagy egyáltalán nem kapunk eredményt. Az új függvényeket néhány egyszerű példán keresztül teszteljük.
2.4 Néhány előredefiniált típus
A 2. táblázat a Haskell-ben használt fontosabb előredefiniált típusokról ad áttekintést.| Bool | True, False |
| Int | -100, 0, 1, 2, ... |
| Integer | -33333333333, 3, 4843056380457832945789457, ... |
| Float/Double | -3.22425, 0.0, 3.0, ... |
| Char | 'a' , 'z', 'A', 'Z', ';', ... |
| String | "Medak", "Navratil" |
2. táblázat: Előredefiniált típusok
2.5 Összegzés
- Egy függvénynek van szignatúrája: egy specifikáció, amely az argumentum(ok) és az eredmény típusait deklarálja
- A sorok elrendezése:
- 1.A legfelsőbb szintű deklarációk az első oszlopban kezdődnek, a végüket a következő jelöli ki, amely szintén az első oszlopban kezdődik.
- 2.A deklarációt bárhol meg lehet törni és a következő sorban folytatni arra figyelve, hogy az beljebb kezdődjön, mint az előző sor.
- 3.Ha a where kulcsszót egynél több deklaráció követi, akkor azok mind ugyanabban az oszlopban kell, hogy kezdődjenek.
- A program szövege legyen annyira tiszta, amennyire csak lehetséges (használj leíró jellegű függvényneveket). Például könnyebb megérteni egy olyan függvényt, amelyet matrixMult-nak hívnak, mint egy olyat, amelyet csak mM-nek.
- Mindemellett a megjegyzések is nagyon hasznosak - minden, ami '--' után áll, az megjegyzés.
- A függvényeket olyan példákkal teszteljük, amelyek kézzel könnyen ellenőrizhetők.
Feladat: Terjeszt ki a programot komplex számokra (egy komplex szám valójában egy valós számpár).
3. Listák, avagy "hogyan lehet hasznos valami, ami ennyire egyszerű?"
Az előző feladatban megismerkedtünk az adattípus-párokkal (pl. (x1,x2) ) és hármasokkal (pl.(a,b,c) ), általánosságban: többesekkel. A pároknak pontosan két elemük van, a hármasoknak pedig pontosan három. Lehet négy, öt, vagy több elemű többesünk, de az elemek száma minden esetben kötött lesz. A többes elemei lehetnek különböző típusúak, pl.:egy pár első eleme lehet név (egy sztring), a második pedig az életkor (egy szám).
Mi az a lista? Listával tetszőleges számú azonos típusú elemet lehet egyszerre kezelni. Egy lista lehet üres is, ennek jele: []. Bármilyen típust tartalmazhat, de minden elemének azonos típusúnak kell lennie. Más szavakkal: a lista azonos típusú (számok, sztringek, Boolean értékek...) elemek egydimenziós halmaza. Néhány példa listára:
[] üres lista
[l, 2] egész típusú elemekből álló lista
[True,False] Boolean típusú elemekből álló lista
[(1,2), (2, 3)] Integer többesekből álló lista
[[1,2], [2, 3, 4]] Integer listákból álló lista
A sztringek is listák:
"Name" = ['N' , 'a' , 'm', 'e']
A lista elemeihez kétféleképpen lehet hozzáférni. A listák első elemeihez (a lista feje) közvetlenül lehet hozzá férni, a többi elemhez viszont csak együttesen (a lista farka). Így ha egy tetszőleges elemhez hozzá akarunk férni, akkor rekurzívan kell olvasnunk a listát. A következő függvény a lista n. eleméhez biztosít elérést:
nthListEl 1 1 = head 1
nthListEl 1 n = nthListE1 (tail 1) (n-1)
3.1 Rekurzió: a funkcionális programozás alapvető elve, avagy "Aki ellopta a hurkokat és a számlálókat"
A faktoriális függvényt (!) a matematikában saját maga felhasználásával definiálják:
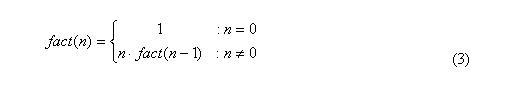
A faktoriális számítás viszonylag egyszerű példa a matematikai indukcióra - a 0 esete és az indukciós lépés (követő eset):
1) p(0),
2) p(n) => p(n+1)
Ezt a szintakszist könnyen lefordíthatjuk Haskell-re:
fact 0 = 1 -- zero step
fact n = n * fact (n-1) -- induction step
Hogyan működik ez a program? Vegyünk egy példát, a 6 faktoriálisát. Mivel n==6, nem a 0-s esetről van szó, tehát az indukciós lépést alkalmazzuk: 6 * fact 5. Mivel n==5 és nem 0, megint az indukciós lépést alkalmazzuk: 6 * (5 * fact 4) , és így tovább, amíg n==0 nem lesz, amikor is a 0-s lépést alkalmazzuk és a rekurzió leáll.
fact 6 ==> 6 * fact 5
==>6 * (5 * fact 4)
==>6 * (5 * (4 * fact 3))
==>6 * (5 * (4 * (3 * fact 2)))
==>6 * (5 * (4 * (3 * (2 * fact 1))))
==>6 * (5 * (4 * (3 * (2 * (1 * fact 0)))))
==>6 * (5 * (4 * (3 * (2 * (1 * 1)))))
==>6 * (5 * (4 * (3 * (2 * 1))))
==>6 * (5 * (4 * (3 * 2)))
==>6 * (5 * (4 * 6))
==>6 * (5 * 24)
==>6 * 120
==>720
A gondolatmenet egyetlen fontos tényre épül: a természetes számok teljes halmaza, beleértve a 0-t is (N0), lefedhető két esettel:
- Egy természetes szám lehet 0 (0-s eset),
- vagy egy másik természetes számot követő természetes szám (indukciós lépés).
A célja ennek a rövid matematikai kitérőnek az, hogy könnyebbé tegye a Haskell-beli listák ehhez hasonló rekurzivitásának megragadását, felfogását. A megfelelő két eset listák esetén:
- Üres lista
- Nem üres lista, mely tartalmaz egy elemet, meg a maradék listát (ez utóbbi lehet üres lista).
A teljes definíciókhoz ismernünk kell még egy fontos függvényt, amely "összeragasztja" az elemeket listává. Ennek jele a (:), kiejtve "cons", mint konstruktor. A típusa a következő:
(:) ::a -> [a] -> [a]
és így működik
1 : 2 : 3 : [] = [1,2,3]
Tehát a két eset, amely lehetővé teszi a listák rekurzív megadását:
[] üres lista
(x: xs) legalább egy elemű lista
List = [] | (a : List)
Ez azt jelenti, hogy egy lista vagy üres, vagy tartalmaz egy elemet és egy azt követő listát (ami megint csak lehet üres ...). Az a típusváltozó arra utal,hogy bármilyen típusú listaelemeink lehetnek[4]. A lista struktúrája nem függ a benne tárolt adatok típusától. Az egyetlen megkötés az, hogy egy lista minden eleme azonos típusú kell, hogy legyen. A listánk állhat egész számokból, Boolean értékekből vagy lebegőpontos számokból, de nem vegyíthetjük a típusokat. Ennek a definíciónak a segítségével már írhatunk listákon működő függvényeket is, például egy olyan függvényt, amely meghatározza a lista elemeinek összegét:
sumList :: [Int] -> Int
sumList [] = 0
sumList (x:xs)= x + sumList xs
Az első elemet rekurzívan elválasztjuk a többitől egészen addig, amíg üres listánk nem marad. Üres listára pedig tudjuk az eredményt: nulla. Ezek után a lista elemeit fordított sorrendben vesszük és összeadjuk, azaz az utolsó elemet adjuk hozzá először a nullához, és így tovább. Ha minden elemen végigmentünk, akkor megkaptuk a lista elemeinek összegét.
A lista-konstruktort arra is használhatjuk, hogy újraírjuk a lista n. elemét kiolvasó függvényünket:
nthListEl' (l:ls) 1 = l
nthListEl' (l:ls) n = nthListEl' ls (n-1)
3.2 A listák alapvető függvényei
| head | a lista első elemét adja vissza |
| tail | elhagyja a lista első elemét |
| length | a lista hosszát adja vissza |
| reverse | megfordítja a listát |
| ++ (concat) | összefűt két listát: [1,2]++[3,4]=[1,2,3,4] |
| map | a lista minden elemére alkalmaz egy függvényt |
| filter | visszaad minden olyan listaelemet, amely teljesíti a megadott feltételt |
| foldr | egyesíti a lista elemeit a megadott függvény szerint, egy megadott kezdőértékkel számolva (pl. összeadja az elemeket) |
| zip | összekapcsolja két lista megfelelő elemeit (amelyek ugyanabban a pozícióban vannak) párokat képezve |
| zipWith | összekapcsolja két lista megfelelő elemeit (amelyek ugyanabban a pozícióban vannak) egy magadott függvényt alkalmazva |
3. táblázat: hasznos függvények listák kezeléséhez
Számos fontos függvény áll rendelkezésünkre, ha listákkal akarunk dolgozni. A 3. táblázat ezek közül mutat be néhányat, valamint röviden megmagyarázza, mit is csinálnak.
A függvények némelyike (mint pl. a map) különösen érdekes, mivel egy függvény az argumentumuk - ezeket a függvényeket magasabb rendű függvényeknek hívjuk. A következőkben néhány ilyen függvényt fogunk alkalmazni.
3.2.1 Kódold a nevedet ASCII számokká és vissza (a map használata)
Tegyük fel, hogy adva van egy sztringünk és szükségünk van minden karakterének az ASCII kódjára. A sztring egy karakterlista a Haskell-ben, így kézenfekvő a lista-függvények alkalmazása a feladat megoldásakor. Az ord függvényt kell minden egyes karakterre alkalmazni, az megadja a hozzájuk tartozó ASCII számot. Mivel a sztring egy karakterlista, ennek az ASCII számokká való kódolásához az ord függvényt minden egyes karakterre alkalmaznunk kell. Ebben lesz segítségünkre a map. A map típusdefiníciója:
map :: (a -> b) -> [a] -> [b]
A map függvénynek két argumentuma van, egy függvény és egy lista, és egy listát ad vissza. A bemeneti lista elemei tetszőleges a típusúak, az eredmény lista elemei pedig szintén tetszőleges b típusúak. Az első argumentumként szereplő függvénynek van egy a típusú paramétere és egy b típusú értékkel tér vissza. A példánkban az a típusnak a karakter felel meg, a b típusnak pedig az egész számok típusa. A map implementációja:
map f [] = []
map f (x:xs) = f x : map f xs
Az f függvényt rekurzívan alkalmazza a lista minden elemére és egy új listát készít belőlük a lista konstruktorának alkalmazásával (':').
Ezek után a függvényünk a következőképpen írható meg:
code :: String -> [Int]
code x = map ord x
A definíciós fájlt újra betöltve a Hugs-ba, már tesztelhetjük is az új függvényünket:
code "Hugs"
Az eredmény:
[72,117,103,115]
3.2.2 Sokszög területének kiszámítása
Tegyük fel, hogy egy sokszög területét kell kiszámolnunk. A sokszög tulajdonképpen x és y koordinátákkal adott pontok listája. A területre vonatkozó Gauss formula szerint:

Számoljuk hát ki a területet a lista-függvények segítségével! A sokszög definiálásával kell kezdenünk. A mi esetünkben ez egy pontokból álló lista, ahol minden egyes pont egy koordinátapáros. A teszteléshez majd a következő sokszöget használhatjuk (azonnal látszik, hogy a területe 10000):
p = [(100.0,100.0),(100.0,200.0),(200.0,200.0),(200.0,100.0)] :: [(Float,Float)]
A p függvény egy egyszerű sokszöget ad vissza, amelyet tehát majd a függvényünk tesztelésére használhatunk.
Először azt kell végiggondolnunk, hogy hogyan építsük fel a listánkat ahhoz, hogy a lista-függvények könnyen alkalmazhatóak legyenek rajta. Az egyértelmű, hogy az utolsó lépés a részterületek összegzése lesz és a kettővel való osztás. A foldl függvény az lista elemeinek egy megadott függvény szerinti egyesítését adja, egy megadott kezdőértékkel számolva. Ha össze akarjuk adni az elemeket, akkor a '+'-t kell használnunk. Mivel a '+' definíció szerint két argumentuma között áll (x+y), '(+)'-nek kell itt írnunk. A '(+) x y' kifejezés ugyanaz, mint az 'x+y'. A függvényünk kezdőértéke legyen nulla. Tehát a függvény a következőképpen nézhet ki:
sum_parts :: [Float] -> Float
sum_parts parts = (foldl (+) 0 parts) / 2
Most a részterületek (xi+ x(i+1))(yi+ y(i+1)) kiszámítására kell találnunk egy módszert. Szeretnénk, ha lenne négy listánk az alábbi tartalommal:
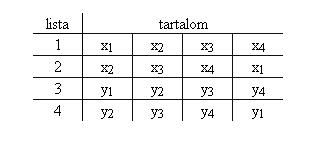
4. táblázat: eredménylisták Így a zipWith segítségével ki tudnánk számítani a részösszegeket. A zipWith függvény a következőképpen definiálható (a függvény nevét zipWith'-re változtattam, hogy elkerüljük a konfliktusokat az amúgy már definiált függvénnyel):
zipWith' ::(a -> a -> a) -> [a] -> [a] -> [a]
zipWith' _ [] _ = []
zipWith' _ _ [] = []
zipWith' f (a:as) (b:bs) = (f a b) : zipWith' f as bs
Az első sor a függvény típusát definiálja. A függvény bemenetként kap két listát és egy függvényt (a listák elemeinek egyesítési módjának leírására). A következő két sor leállítja a rekurziót, ha bármelyik lista kiürült. Az utolsó sor írja le a függvény működését. Fogja a listák első elemeit és alkalmazza rájuk az f függvényt. Az eredmény a kimeneti lista egy eleme lesz.
A Gauss-formula megvalósításából már csak egy rész maradt ki: vegyük az első pont x koordinátáját és vonjuk ki belőle a második pont x koordinátáját (xi + x(i+1)). Ha a 4. táblázat listáit használjuk, akkor az első lista elemeit vesszük és kivonjuk belőlük a második lista elemeit. Így a
zipWith (-) list1 list2
sorral elvégezhetjük a kivonást a listák összes elemére. Ezek után a teljes formula a következőképpen alakul:
zipWith (*) (zipWith (-)
list1 list2) (zipWith (+) list3 list4)
Az egyetlen fennmaradó probléma a 4. táblázat listáinak előállítása. Az 1. és a 3. lista igen egyszerű, ugyanis azok a pontok x illetve y koordinátái. A map segítségével két új függvényt, az fts-t és az snd-t alkalmazhatjuk a sokszög pontjainak eredeti listájára. Az fst függvény fog egy párt és visszaadja annak az első tagját. Az snd hasonlóan működik, csak a pár második tagját adja vissza. Ha feltesszük, hogy a koordináták (x,y) sorrendben adottak, akkor az 1. és a 3. listát a következőképpen kaphatjuk meg:
list1 poly = map fst poly
list3 poly = map snd poly
Itt a poly a sokszöget megadó lista. Mivel a (4)-es formula akkor is működik, ha felcseréljük x-et és y-t, nem számít, hogy a sokszög pontjainak koordinátái milyen sorrendben vannak megadva.
A két másik lista előállítása már egy kicsit bonyolultabb. Mindkét esetben a lista el van forgatva. Tehát fognunk kell az első elemet és a lista végére kell fűznünk. Erre egy lehetőség:
moveback poly = tail poly ++ [head poly]
A head és függvények a listát két részre bontják: az első elemre (head) és a maradékra (tail), ami maga is egy lista. Ha egy kifejezés köré szögletes zárójeleket rakunk, akkor abból listát csinálunk, aminek az eleme maga a kifejezés lesz [5]. A ' ++ ' függvény (vagy concat, mint konkatenáció) fog két listát és egyesíti őket úgy, hogy a második lista elemeit az első lista utolsó eleme után fűzi.
A fenti kódrészletek kombinációja kiadja magát a végső függvényt, amelybe még hibakezelést is építettünk erre az esetre, ha háromnál kevesebb pontot kapna a függvény bemenetként (akkor nincs terület):
area :: [(Float,Float)] -> Float
area [] = error "not a polygon"
area [x] = error "points do not have an area"
area [x,y]= error "lines do not have an area"
area ps = abs ((foldl (+) 0.0 parts) / 2) where
parts = zipWith (*) (zipWith (-) l1 l2) (zipWith (+) l3 l4)
l1 = map fst ps
l2 = tail l1 ++ [head l1]
l3 = map snd ps
l4 = tail l3 ++ [head l3]
3.3 Egyéb hasznos listakezelő függvények
Mint arról már a 3.2 részben is volt szó, a függvényeknek lehet függvény argumentumuk is. Erre példa a map függvény, amelyet a 3.2.1 részben használtunk:
map :: (a-> b) -> [a] -> [b]
map f [] = []
map f (x:xs) = f x : map f xs
A függvénydefinícióhoz nem kell explicite tudnunk, hogy milyen típusokat használunk. Futásidőben azonban fontos, hogy már mindkét típust ismerjük. Futásidőben már konkréten létező adatokkal dolgozunk, amelyeknek meghatározott típusaik vannak, így ekkor már ismerjük a paraméterek típusait. Az eredmény típusának azonban egyértelműnek kell lennie. Ebben az esetben specifikálnunk kell a kívánt eredmény típusát a ':: Type' hozzáadásával.
A következő fontos és megismerendő függvény a filter (szűrő). Átnevezve implementáltuk a már definiált függvénnyel való ütközés elkerülése végett:
filter2 :: (a->Bool) -> [a] -> [a]
filter2 f [] = []
filter2 f (x:xs) = if f x then x : filter2 f xs
else filter2 f xs
A szűrő függvénynek két argumentuma van. Az első egy függvény (maga a szűrő), a második egy tetszőleges a típusú lista. A szűrő kap egy listaelemet és egy Boolean éréket ad vissza. Ha ez az érték True, akkor az adott elem a listában marad, máskülönben nem fog szerepelni az eredménylistában.
3.4 Másodfokú egyenletekből álló lista gyökeinek számítása
Van egy másodfokú egyenletekből álló listánk (valós számhármasokként tárolva, mint a 2.3-as részben). A feladat két részre oszlik. Biztosítanunk kell, hogy minden egyenletnek valósak a megoldásai, mert ha komplex megoldások adódnának, akkor a függvényünk hibaüzenetet adna. Tehát szükségünk van egy olyan függvényre, amely True-t ad vissza, ha a gyökök valósak és False-t, ha a gyökök komplexek:
real :: (Float, Float, Float) -> Bool
real (a,b,c) = (b*b - 4*a*c) >= 0
A fenti függvényt használhatjuk azoknak az egyenleteknek a kiszűrésére, amelyek gyökei valósak:
p1 = (1.0,2.0,1.0) :: (Float, Float, Float)
p2 = (1.0,1.0,1.0) :: (Float, Float, Float)
ps = [p1,p2]
newPs = filter real ps
rootsOfPs = map roots newPs
A ps függvény egy két másodfokú egyenletet tartalmazó listát ad vissza. Az első egyenletnek (p1) valósak a gyökei, míg a másodiknak (p2) komplexek. A newPs függvény a real függvény segítségével kigyűjti ps-ből azokat az elemeket, amelyeknek valósak a gyökei. Végül a rootOfPs a roots függvényt alkalmazza a listában maradt egyenletekre. Az eredmény tehát az egyenletek megoldásainak listája lesz.
Feladat: Alkalmazd a komplex gyököket számoló függvényt (az előző feladatból) másodfokú egyenletek listájára!
3.5 Alternatív függvénydefiníció
Egy függvényt mindig többféleképpen is meg lehet írni. A különbségek általában a definíció absztrakciójában jelennek meg vagy a felhasznált függvények halmazában. A speciális eseteket is többféleképpen lehet kezelni. A következő példában egy lista hosszának a kiszámolására definiálunk függvényeket. Bár igen eltérően néznek ki, mégis ugyanazt az eredményt adják. Az absztrakció minden esetben egyforma (minden függvénynek van egy [a] típusú paramétere és egy Int típusú eredménye).
l1 [] = 0
l1 (x:xs) = 1 + l1 xs
l2 xs = if xs == [] then 0
else 1 + l2 (tail xs)
l3 xs | xs == [] = 0
| otherwise = 1 + l3 (tail xs)
l4 = sum . map (const 1)
l5 xs = foldl inc 0 xs
where inc x _ = x+1
l6 = foldl' (\n _ -> n + 1) 0
A speciális eset ebben a feladatban az üres lista esete. Az üres lista hossza nulla. Az l1, l2l3 függvények ebből a tényből indulnak ki és iteratívan számolják ki a lista hosszát. A különbség az, hogy másképpen detektálják az üres listát:
- Az l1 mintaillesztést alkalmaz,
- az if-then-else elágazást használ,
- az "őröket" használ (ld. 6.2).
Az l4, l5 l6 függvények más-más lista-függvényeket hívnak segítségül a számoláshoz:
- Az l4 először minden listaelemet 1-re cserél. majd egyszerűen összeadja a lista elemeit.
- Az definiál egy lokális függvényt, amely agy lokális számlálót léptet és a foldl függvény segítségével megy végig a listán.
- Az l6 az l5-höz hasonlóan jár el, csak a függvény egy lambda-kifejezésben definiálja[6].
3.6 Összefoglalás
Ebben a fejezetben a listákkal foglalkoztunk. A legfontosabbak még egyszer:
- A listák tökéletesek tetszőleges számú elem együttes reprezentálására, feltéve, hogy az elemek azonos típusúak.
- Sok hasznos listákkal foglalkozó függvény található a prelude.hs-ben.
- A magasabb rendű map függvény egy adott függvényt alkalmaz egy lista minden elemére.
- A rekurzió alapvető elméleti háttere a matematikai indukció.
- A rekurzió az imperatív programozás hurkait helyettesíti matematikai úton.
- A listák izomorfak a valós számokkal és így a rekurziót is ugyanúgy alkalmazhatjuk rajtuk.
- A map, filter, foldl/foldr függvények a listákat kezelő függvények közül a legfontosabbak és sok alkalmazásban igen hasznosak.
- Általában többféleképpen lehet egy függvényt Haskell-ben definiálni.
4. Adatreprezentáció
Eddig csak az alapvető típusokat használtuk függvényeinkben. Általánosságban szükségünk lehet adatstruktúrák definiálására, hogy azokban tároljuk megfelelő formában a függvényünknek szükséges adatokat.
4.1 Típusszinonimák
Folytassuk a másodfokú egyenleteket megoldó példát! A bemenet egy hármas (Float,Float,Float), a kimenet egy pár (x1,x2). A roots függvényre a típusszignatúra így nézett ki:
roots :: (Float, Float, Float) -> (Float, Float)
Ha a programunkban több függvény is lenne, akkor az a fajta típusinformáció nem sokat segítene annak megértésében, hogy mint csinál ez a függvény. Jobb lenne valami következőt látni:
roots :: Poly2 -> Roots2
Ezért s Haskell támogatja a típusszinonimákat. A szinonimák felhasználok által megadott nevek már létező típusokra illetve azokból álló többesekre és listákra. A
type Poly2 = (Float, Float,Float)
type Roots2 = (Float, Float)
sorok azt jelentik, hogy ezután minden Float-okból álló hármasra hivatkozhatunk a Poly2 néven, a szintén Float-okból álló párokra pedig Roots2 néven. Mindekét elnevezésre igaz, hogy többet mondanak a típusról, mint az eredeti többesek leírása (a Poly2 névből megtudhatjuk, hogy egy másodfokú polinom együtthatóiról van szó, a Roots2 pedig nyílván egy ilyen polinom gyökeit tárolja).
Összegzés: A típusszinonimák csak már létező típusokhoz biztosítanak elérést. Céljuk, hogy világosabbá tegyék egy program működését illetve azt, hogy egy adott függvénynek mik e bemenetei és kimenetei.
4.2 Felhasználók által definiált adattípusok
Előre definiált típusok (Bool,Int,FloatChar) összeépítése listákba ([])vagy többesekbe (pár, hármas, ...) sokszor bizonyul nagyon hatékony megoldásnak a legkülönbözőbb feladatoknál. Mégis néha saját definíciókra van szükségünk:
- Többesek kényelmesebb formában: Poly = (Float,Float,Float)
- Felsorolás típusok: pl. a hét napjai
- Rekurzív típusok: Num (N0) vagy nulla, vagy a Num-ra következő elem
A felhasználók által definiált adattípusok fontos szerepet játszanak az osztályalapú programozási stílusban, ezért érdemes megtanulnunk, hogyan működnek.
data Polynom = Poly Float Float Float
Magyarázat:
- Az adattípus definiálást a data kulcsszóval kezdjük
- A típus neve Polynom (ez hordozza a típusinformációt)
- A Poly a konstruktor függvény (próbáld ki a ':t Poly'-t)
- A első, második és harmadik argumentumának típusa
Ezek után újraírhatjuk a roots függvényt roots2 néven (hogy elkerüljük az ütközést):
roots2 :: Polynom ->(Float, Float)
roots2 (Poly a b c) = ...
pOne, pTwo:: Polynom
pOne = Poly 1.0 2.0 1.0
pTwo = Poly 2.0 4.0 (-5.0)
A -5.0 körüli zárójelek a pTwo definícióban ezért kellenek, mert a negatív számok jelölésére használt jel megegyezik a kivonás jelével. A zárójelek nélkül az interpreter félreértené a kódot és a következő hibaüzenetet generálná:
ERROR D:\Texte\Latex\code.hs:116 - Type error in explicitly typed binding
*** Term : pTwo
*** Type : Float -> Polynom
*** Does not match : Polynom
A legfontosabb, hogy jól meg tudjuk különböztetni a típus nevét (Polynom) a konstruktortól (Poly). A típusnév mindig a típusinformációval kapcsolatos sorokba kerül (amelyek tartalmazzák a '::'jelet), a konstruktor pedig az alkalmazással kapcsolatos sorokba (amelyek tartalmazzák a '=' jelet). A típuskonstruktor az egyetlen függvény, amelynek nagy betűvel kezdődik a neve és az egyetlen olyan, amely a kifejezések baloldalán is szerepelhet.
A konstruktor neve megegyezhet a típus nevével, de ez nem ajánlott.
Fontos! Végül egy kis szintaktikai cukor. Hogy elkerüljük a függvények eredményeinek kiíratásával kapcsolatos problémákat, csak két szót kell minden új adattípus definíciójához hozzátennünk: deriving Show. így automatikusan generálunk a Show osztályból[7] egy példányt az új adattípusunk számára.
A következő kódrészlet a rekurzív adattípusra ad példát. Próbáld ki a parancssorban!
:t Start, :t Next, :t Next (Bus), :i Bus, testbus, testint
data Bus = Start | Next (Bus) deriving Show
myBusA, myBusB, myBusC :: Bus
myBusA = Start
myBusB = Next (Next (Next (Start)))
myBusC = Next myBusB
plus :: Bus -> Bus -> Bus
plus a Start = a
plus a (Next b) = Next (plus a b)
testBus :: Bus
testBus = plus myBusC myBusB
howFar :: Bus -> Int
howFar Start = 0
howFar (Next r) = 1 + howFar r
testInt :: Int
testInt = (+) (howFar myBusC) (howFar myBusB)
4.3 Paraméteres adattípusok
Az adattípusokat típusparaméterekkel lehet paraméterezni, melyeknek a típus használatakor már példányosítottnak kell lenniük. Ilyen adattípusra egyszerű példa a lista:
data List a = L a (List a) | Empty
Ezzel a listát mint rekurziót definiáltuk. A kezdőérték az üres lista. Minden más listának van egy eleme, ami lista feje és egy farka, ami maga is lista. A lista elemei tetszőlegesek, de azonos típusúak. Néhány példa:
l1,l2,l3:: List Integer
l1 = Empty
l2 = L 1 l1
l3 = L 5 l2
li1 = L 1.5
Empty :: List Double
5. Polimorfizmus
Polimorfizmusról akkor beszélünk, ha egyetlen függvény többféle argumentumtípusra is alkalmazható. Tipikus példa erre más programozási nyelvekben az összeadás és kivonás művelete. Általában a következő kifejezések vonatkozhatnak egészekre és lebegőpontos számokra is. C++-ban azt mondanánk, hogy a függvények "túlterheltek".
a + b
a - b
5.1 Ad hoc polimorfizmus
Ha két műveletnek csak ugyanaz a neve, akkor ad hoc polimorfizmusról beszélünk. Ez igazából zavaró eset, hiszen két különböző művelet, különböző tulajdonságokkal használhatja ugyanazt a nevet (pl. a '+' sztringek összefűzésénél nem kommutatív: a + b nem egyenlő b + a). Ez így nem szerencsés, a programozóknak nagyon oda kell figyelniük, hogy elkerüljék az ebből adódó hibákat (pl. az kód olvasója mást vár a '+'-tól, mint ami annak a programbeli szerepe).
5.2 Részhalmaz polimorfizmus
A polimorfizmus egyik gyakori fajtája az adattípusok egy részhalmaz relációján alapul. Vegyünk alapul egy teljesen általános típust (mondjuk a számokat), amelyből altípusok konstruálhatóak (Integer, Float, stb.). Ezek után azt mondjuk, hogy az összeadás művelete a szám típus minden objektumára alkalmazható, tehát az altípusaira is.
Altípus relációk nem definiálhatóak közvetlenül a Haskell-ben. Az azonban egy lehetséges követelmény, hogy a használt adattípushoz létezzenek specifikus osztály-példányok. A roots példában valós számokra van szükségünk paraméterként és eredményként is. Mivel a valós számok implementálása nem lehetséges számítógépes rendszerekben, közelítésekkel kell dolgoznunk (pl. lebegőpontos számok). Emellett megkövetelhetjük, hogy bizonyos függvények - összeadás, szorzás, gyökvonás, ... - legyenek definiálva az éppen használt adattípusra. Ezek a függvények a Haskell Num (számok),Fractional és Floating osztályaiban vannak definiálva. Tehát elegendő megkövetelni a Floating implementációját:
roots :: (Floating a) => (a, a, a) -> (a, a)
A '(Floating a) =>' hozzáadása nem generálja a szükséges példányt! Csak leellenőrizheti a példány létezését futásidőben (amikor már egyértelmű, hogy melyik adattípust is használjuk) és generálhat hibaüzenetet (Unresolved Overloading), ha a szükséges példány nem létezik.
? roots (1,2,1)
ERROR - Unresolved overloading
*** Type : Floating Integer =>(Integer,Integer)
*** Expression : roots (1,2,1)
?
5.3 Paraméteres polimorfizmus
A fenti problémára a Haskell-ben használt megoldás a 'paraméteres polimorfizmus'. Egy művelet
plus :: a -> a -> a
alkalmazható minden olyan szituációban, ahol az a paraméter konzisztensen ugyanarra a típusra van cserélve, mint pl.:
plus :: Int -> Int -> Int,
vagy
plus::Rat -> Rat -> Rat.
Ennek megfelelően az adattípusoknak is lehetnek típus paramétereik (pl.: data List a).
Ez jó lehetőségeket biztosít, mert a műveleteket általános formában is ki lehet fejezni, a választott paraméter sajátságaitól függetlenül. Például meg lehet nézni egy lista hosszát anélkül, hogy tudnánk, milyen típusú elemeket is tartalmaz.
listlen :: List a -> Int
listlen Empty = 0
listlen (L _ list) = 1 + listlen list
6. Haladó programozási módszerek
6.1 Kompozíció
Legutóbbi példánkban két függvényt alkalmaztunk egy listára. Ennek a matematikai kifejezésére az f (g(x)) szolgál. Vagy azt is írhatjuk, hogy (g°f )(x). A legfontosabb feltétel az, hogy a 'g' függvény eredményének típusa egyezzen meg az 'f ' függvény argumentumának típusával. A Haskell-ben ez igen hasonlóan működik. A kompozíció operátora a '.', amely fog két függvényt és összekapcsolja őket ((f . g) x = f (g x)).
rootsOfPs2 = (map roots.filter real) ps
A pont operátor helyettesíti a matematikában használatos kör operátort. A filter real függvény felel meg a g függvénynek, a map roots az f-nek, az x változó pedig jelen esetben a ps.
6.2 Őrök
Az őrökkel if-then-else kifejezéseket lehet másképpen leírni. Tegyük fel, hogy adva van az alábbi példánk:
tst1 (a,b,c) = if d > 0
then d
else if d==0 then 0
else error "negative sqrt"
where d = b*b - 4*a*c
Őrök használatával ugyanez a következőképpen nézne ki:
tst2 (a,b,c) | d > 0 = d
| d == 0 = 0
| otherwise = error "negative d"
where d b*b - 4*a*c
Ha az első teszt (d > 0) True-t ad vissza, akkor az eredmény d, ha nem, akkor a második sor feltételét ellenőrizzük. Az eredmény ekkor nulla. Az otherwise kifejezés a harmadik sorban egy előre definiált kifejezés a Haskell-ben, mely minden esetben True-val tér vissza. így tehát ha az első két sor ellenőrzése False-szal tér vissza, akkor a függvény eredménye egy hibaüzenet lesz. Látható tehát, hogy a tst2 eredménye minden esetben megegyezik a tst1 eredményével.
Az őrök nagyon hasznosak lehetnek nem folytonos, szakaszos függvényeknél. Tegyük fel, hogy van egy függvényünk, amely értéke negatív számokra -1, a nullára 0, pozitívokra pedig 1 (azaz a signum függvény). A függvény matematikai definíciója a következőképpen néz ki:
KEP 5
Ez őrökkel felírva (a nevet sign-re változtattuk a már létező signum függvénnyel való ütközés elkerülése végett):
sign x | x < 0 = -1
| x == 0 = 0
| x > 0 = 1
Látható, hogy csak apró különbségek vannak a matematikai jelölés és a Haskell szintaxis között: függőleges vonalkák helyettesítik a kapcsos zárójelet, valamint a feltétel és az eredmény fordított sorrendben szerepel.
6.3 Szekciók
A standard numerikus függvényeknek két argumentumuk van és egyetlen eredményük:
(+), (*) :: Num a => a -> a -> a
Alkalmazásuk a következőképpen történik:
?3+4
7
de így is írhatnánk:
? (+) 3 4
7
Ha az első argumentumot az operátorral együtt specifikáljuk, akkor a típusszignatúra:
(3 +) :: Num a => a -> a
Más szavakkal az '(+)' első argumentumát "megette" a 3-as szám. Ez a tulajdonság map-es konstrukcióknál lehet hasznos:
? map (3+) [4,7,12]
Az egyenlőség (==) és a rendező operátorok (<, <=, >, >=) egy másik olyan függvényhalmazt alkotnak, mely széleskörűen alkalmazott a szekciós formában. Mivel Boolean értéket adnak vissza eredményként, az ő szekciójuk a filter-es konstrukciókban válik hasznossá:
? filter (==2) [1,2,3,4) [2]
? filter (<=2) [1,2,3,4] [1,2]
Figyeljük meg az operátor és az argumentum megváltozott helyzetét ebben a szekcióban! Szimmetrikus operátorok esetén nincsen különbség, de a sorrendező operátoroknál van. Próbálgasd a következőket a 'filter p [1,2,3,4]'-ban a p helyén és figyeld meg, mi történik:
(<2) (2<) (>2) (2>)
Ősszegzés: Szekciók használatával egy meglévő függvényt olyan új függvénnyé lehet konvertálni, amelynek kevesebb argumentuma van, mint az eredetinek volt. Gyakran használják olyan függvények létrehozására, amelyek alkalmasak a map, a filter és a függvénykompozíció bemeneti függvényeként szerepelni.
6.4 Lista felfogások
A lista felfogások még egy eszközt az eddigiek mellé, amivel listákat lehet definiálni és műveleteket végrehajtani rajtuk (általában megtalálható a funkcionális programozásról szóló tankönyvekben). A forma teljesen természetesen adódik, ha a listákra a halmazok fogalmai szerint gondolunk.
A halmazelméletben a 0 és 100 közé eső páratlan számokat a következő halmaz reprezentálja: {x | x Î 0..100, x páratlan}. A funkcionális nyelveken ez így írható:
[x | x <- [0..100], odd x]
Tehát a kapcsos zárójelek helyére szögletesek kerülnek, az 'Î' jel helyére a '<-' jel és máris szinte bármilyen kifejezést definiálhatsz halmazként.
Például ha egy lista minden elemét meg akarjuk szorozni egy másik lista minden elemével, akkor a következő függvényt írhatjuk:
? f [2,3,4] [5,6] where f xs ys = [x*y | x <- xs, y <- ys]
[10,12,15,18,20,24] :: [Integer]
A map és filter függvényeket is ki lehet így fejezni:
map f xs = [f x | x <- xs]
filter p xs = [x | x <- xs, p x]
7. Funkcionális programozás vs. imperatív programozás
Példa: vektorok skaláris szorzatának számítása. Legyenek a és b egydimenziós vektorok, a elemei a1, a2, ..., an, b elemei b1, b2, ..., bn. A skaláris szorzatuk a megfelelő komponensek szorzatainak összege:
a× b = a1 b1 + a2 b2 + ... + an bn .
Imperatív programban ez valahogy így nézne ki:
c := 0
for i:= 1 to n do
c := c + a[i] * b[i]
Több olyan hely is feltűnhet, ahol hiba lehetséges. Szükségünk van egy változóra a részeredmények tárolásához. Ez a változó az egész függvényen belül aktív lesz és így máshol is használható. Ez nehezen olvashatóvá teheti a programot és hibákhoz is vezethet, ha a programozó nem elég elővigyázatos. A vektor elemeinek számát már a for-do hurok előtt meg kell adnunk, mivel az a hurok második paramétere. Végül megjegyzendő még az, hogy elveszítjük a kapcsolatot a matematikai jelöléssel :
valami
Egy funkcionális programban többféle megoldást is választhatunk. Itt van az egyik legrövidebb és legelegánsabb:
inn2 :: Num a => ([a] , [a]) -> a
inn2 = foldr (+) 0 . map (uncurry (*)) . uncurry zip
Sok furcsának tűnő dolog van ebben a két sorban. Ha eltekintünk a Num a => -től, akkor az első sor tiszta. Ez a rész megmondja az interpreternek, hogy a tetszőleges a típusnak számnak kell lennie. A Num egy osztály, amelyben összeadó, kivonó, szorzó, stb. függvények találhatók. Nincs szükségünk nem szám típusokra is megadni ezt a függvényt. Tehát az adat szám típusú, ha a Num-nak van annak típusára implementációja. Tehát az interpreter ezt ellenőrzi.
A második sorban nincs a függvénynek paramétere. A teljes sor így nézhetne ki:
inn2 x = (foldr (+) 0 . map (uncurry uncurry zip) x
Ha összevetjük az '=' jel bal- és jobboldalát, akkor láthatjuk, hogy mindkét esetben az x az utolsó elem. Ilyen esetben következmények nélkül elhagyhatjuk a kérdéses paramétert. Ez nem csak azt jelenti, hogy kevesebbet kell gépelnünk, hanem azt is lehetővé teszi, hogy az igazán fontos részekre koncentráljunk - magára az algoritmusra.
A második sorban három függvény kompozíciója szerepel:
- uncurry zip: a zip függvény két listát kap paraméterként és egyesíti azokat a következőképpen: fogja az első elemet mindkét listából és pár képez belőlük. Ez lesz az eredménylista első eleme. Aztán fogja mindkét lista második elemét, azokból is pár képez (ez lesz az eredménylista második eleme), stb. Az uncurry függvény úgy módosítja a zip függvényt, hogy nem két külön bemenő listája lesz, hanem egy pár. Az uncurry használatára később még mutatunk példát (ut függvény).
- map (uncurry (*)): ez a rész fogja az első lépésben keletkezett többeseket és megszorozza azok elemeit. Egyetlen többesre az uncurry (*) is elég lenne a művelet elvégzéséhez. A map függvény azért kell, hogy a művelet végrehajtódjon minden egyes többesen.
- foldr (+) 0: végül ez a függvény adja össze a szorzások eredményeit.
A jobb megértés érdekében próbáld ki az alábbi példákat és figyeld meg, mit csinálnak:
ft = foldr (*) 7 [2,3]
ut = uncurry (+) (5,6)
zt = zip "Haskell" [1,2,3,4,5,6,7]
testvec = inn2 ([1,2,3], [4,5,6])
A következő lépés a függvény kiterjesztése vektorok listájára. Tehát a függvényünk bemenő paramétere legyen vektorok (azaz egész számok listája) listája. Az eredmény a vektorok skaláris szorzata lesz:
innXa, innXb :: [[Integer]] -> Integer
innXa = foldr (+) 0 . map (foldr (*) 1) . transpose
innXb = foldr1 (+) . map (foldr1 (*)) . transpose
Az innXa és innXb függvények ugyanazt csinálják. Mindkettő három részből áll. A különbség csupán az, hogy az innXb a foldr1 függvényt használja a foldr helyett. A foldr1 a paraméterként szereplő függvényhez definiált neutrális elemet használja. Szorzás esetén ez 1, összeadás estén pedig 0.
A transpose függvény listák listáját kapja paraméterül és egy új listák listáját állít elő. Az első lista a bemeneti listák első elemeit tartalmazza, a második lista a bemeneti listák második elemeit tartalmazza, stb.
transpose :: [[a]] -> [[a]]
transpose [] = []
transpose ([]:xss) = transpose xss
transpose ((x:xs) : xss) = (x : [h | (h:t) <- xss]) :
transpose (xs : [t | (h:t) <- xss])
A következő példával tesztelhetjük függvényünket:
x = [[1,2,3],[4,5,6],[1,1,1]]
testa = innXa x
testb = innXb x
Nézzük tehát, hogy milyen előnyeit fedeztük fel a funkcionális programozásnak az imperatív programozással szemben:
- Csak a saját argumentumain dolgozik (nincsenek mellékhatások).
- Hierarchikus, azaz egyszerű függvényekből építkezünk.
- Olyan függvényeket használ, amelyek általában más programokban is hasznosak lehetnek.
- Statikus és nem ismétlődő.
- Teljesen általános.
- Nem ad nevet az argumentumainak.
8. Egyszerű adatbázis építése
Az adatbázis azonosítókkal és attribútumokkal ellátott elemek gyűjteménye. Azonosítóként egész számokat fogunk használni. Ezeknek egy adatbázison belül egyedieknek kell lenniük. Az attribútumok értékhalmazokhoz ('név', 'kor', 'szín') értékeket ('John', '1211', 'red') rendelő függvények.
A szükséges műveletek:
- insert (beszúr egy új objektumot néhány attribútummal az adatbázisba)
- select (azaz kiválasztás, adott azonosítóhoz visszaadja az objektumot)
- selectby (feltételes kiválasztás, azaz a feltételeket kielégítő objektumokat adja vissza)
A specifikáció-kifejtési eljárás vizsgálata a célunk: Tetszőleges adattípusokat tartalmazó szignatúrákkal definiáljuk a függvényeket és csoportosítjuk őket. Az eredménycsoportok az úgynevezett osztályok. Később majd definiáljuk ezeket a függvényeket specifikus adattípusokra is (osztályok példányai).
Alapértelmezett definíciókat adunk meg általános műveletekre, amelyek nem függnek az implementációs részletektől - len a 3.1-es fejezetben.
Ha így dolgozunk, akkor az osztályainkat különböző programozók is használhatják, munkájuk eredményei kompatibilisek lesznek egymással (bár az implementációk eltérhetnek).
Az egyszerűség kedvéért bevezetünk két típusszinonimát az azonosítókra és az attribútumokra. Az azonosító egy Integer Az attribútum két sztringből áll, ezek közül az első az attribútum típusát adja meg, a második pedig az értékét.
type ID = Int
type Attrib = (String, String)
Az Objects osztály az objektumok viselkedését definiálja. Definíció szerint egy objektum tartalmaz egy ID típusú azonosítót és egy Attrib típusú attribútumokból álló listát. Bizonyos műveletek (object: létrehoz egy új objektumot; getID: visszaadja az objektum ID-jét; getAttrib: visszaadja az objektum attribútumait) implementáció-függőek, ezért egy példányban definiálni kell őket használat előtt. De például a getName művelet (a "név" attribútum értékét adja vissza) nem függ az implementációtól, ezért használhatjuk az alapértelmezett definícióját (egy axióma).
class Objects o where
object :: ID -> [Attrib] -> o
getID :: o -> ID
getAtts :: o -> [Attrib]
getName :: o -> String
getName = snd . head . filter (("name"==) . fst) . getAtts
A Databases osztály az objektumok egy gyűjteményének viselkedését specifikálja. Nem lényeges, hogy milyen típusú az objektum feltéve, hogy vannak arra a típusra műveletek definiálva az Objects osztályban. Az első öt művelet, csak úgy, mint ez előbb, függ az implementációtól.
class (Objects o) => Databases d o where
empty :: d 0
getLastID :: d o -> ID
getObjects :: d o -> [o]
setLastID :: ID -> d o -> d o
setObjects :: [o] -> d o -> d o
insert :: [Attrib] -> d o -> d o
insert as db = setLastID i' db' where
db' = setObjects os' db
os' = o : os
os = getObjects db
o = object i' as
i' = 1 + getLastID db
select :: ID -> d o -> o
select i = head . filter ((i==).getID) . getObjects
selectBy :: (o -> Bool) -> d o -> [o]
selectBy f = filter f . getObjects
Most már megvan egy egyszerű adatbázis teljes specifikációja. A következő lépés egy implementáció elkészítése a specifikáció tesztelésére. Az itt bemutatott megoldás csak egy a sokféle lehetséges közül:
Először is az objektumok egy részletes reprezentációjára van szükségünk. Definiáljuk az Object adattípust (azonosítóval és attribútumokkal) és az Object osztályhoz kötjük, azaz implementáljuk az osztályt erre a típusra. Csak azokat a függvényeket kell implementálnunk, amelyekre nincs axiómánk az osztálydefinícióban.
data Object = Obj ID [Attrib] deriving Show
instance Objects Object where
object i as = Obj i as
getID (Obj i as) = i
getAtts (Obj i as) = as
Látható, hogy minden implementáció-függő függvénynek szoros kapcsolata van az adattípussal. A függvények vagy kiolvasnak egy adatot az adathalmazból és azt adják vissza eredményként, vagy adatot írnak az adathalmazba és magát az adathalmazt adják vissza eredményül. Tehát nem nehéz ezeket a függvényeket implementálni. A komplex feladatok (mint pl. egy specifikus attribútum olvasása) az osztálydefiníciók részei.
Az adatbázissal is hasonlóan kell eljárnunk. Az adatbázis adathalmaza egy azonosítóból és objektumok listájából áll. Az adathalmazban tárolt azonosító az utolsó azonosító, amelyet egy objektum használt, ezért könnyű egy új objektumra az azonosító kiszámolása:
data DBS o = DB ID [o] deriving Show
instance Databases DBS Object where
empty = DB 0 []
getLastID (DB i os) = i
setLastID i (DB j os) = DB i os
getObjects (DB i os) = os
setObjects os (DB i ps) = DB i os
Most már elkezdhetjük az adatbázis tesztelését. Tesztelési célra ilyen jellegű példákat használunk:
d0, d1, d2 :: DBS Object
d0 = empty
d1 = insert [("name", "john"),("age", "30")] d0
d2 = insert [("name", "mary"),("age", "20")] d1
test1 :: Object
test1 = select 1 d1
test2 :: [Object]
test2 = selectBy (("john" ==).getName) d2
A tesztek a választott implementációhoz kapcsolódnak.
9. Modulok
Az eddigi programok rövidek és tömörek voltak, ráfértek volna egyetlen lapra is. Ha komolyabb programokat szeretnénk írni, akkor nagyon valószínű, hogy a programjaink mérete meg fog nőni. Egy hosszú fájl áttekintése pedig nehéz feladat. Ezért hosszú projekteket inkább olyan részekre bontunk, amelyek szorosan összetartozó programrészleteket tartalmaznak. Ezeket a részegységeket moduloknak hívják (nem csak a Haskell-ben).
Hogyan írjunk modult? Ez igazán egyszerű, csak egy sort kell beírnunk a module kulcsszóval és az aktuális modul nevével (nagy kezdőbetűvel!), utána a where kulcsszót és ennyi az egész. Jegyezzük meg, hogy ennek a sornak a Haskell szkript első olyan sorának kell lennie, ami nem megjegyzés vagy üres sor. Egy példa:
-- filename: Test.hs
-- project : Haskell Script
-- author : Damir Medak
-- date : 10 June 1999
module Test where
data Person = Pers String Int
-- etc.
-- end of file
Néhány hasznos konvenció:
- Egy fájlba pontosan egy modult rakj!
- A moduloknak és a fájloknak legyen azonos a nevük!
Tehát a fenti példát Test.hs néven érdemes fájlba menteni.
Csak a Haskell definíciók összegyűjtése jól elnevezett modulokba még nem biztosítaná azt a kifejező erőt, amit el akarunk érni. A legfontosabb, hogy megtanuljuk, hogyan lehet más modulokban levő definíciókat a konkrét modulunkba importálni. Importálhatunk függvényt a számos Haskell könyvtárból és a saját korábbi, modularizált munkáinkból is. A továbbiakban mindkettőre mutatunk példát.
9.1 Már létező definíciók importálása
A modulkezelés gyakorlására jó feladat egy olyan, már definiált függvénynek a használata, amelyet nem a prelude.hs biztosít nekünk. Példaként tekintsük a sort függvényt, amely a '\hugs\Lib\List.hs' szkriptben van definiálva. Ki kell kötnünk, hogy a List modult (meglepetésre éppen úgy hívják, mint a 'List.hs' szkriptet) importáltuk a saját modulunkba.
module Test01 where
import List
xs = [2,1,4,3,5]
ys = sort xs
--end of file
Ments el egy modult 'Test01.hs' néven és töltsd be a Hugs-ba! Figyeld meg, mely fájlok töltődnek be. Ha azt a kellemetlen hibaüzenetet kapnánk, hogy "module List not previously loaded", akkor gépeljük be, hogy ":s i+", üssük le az ENTER-t az interpreterben és az üzenet nem jelenik meg újra.
9.2 Fájlok összekapcsolása projektté
Van egyszerű szabály az importált modulok deklarálásának írásakor: minden modulban importálni kell azokat a modulokat, amelyeknek függvényeit használja a definíciójában.
Ha a moduljaink teljese függetlenek, akkor lehet, hogy egyetlen projektfájlba importáljuk az összes többi fájlt a következőképpen:
module Project where
import Part01
import Part02
import Part03
--end of import
ahol a deklarációs részek az alábbiak:
module Part01 where
--etc.
module Part02 where
--etc.
module Part03 where
--etc.
Általában néhány függvényt minden modul használ. Ilyen esetben minden modulban importálni kell azt a modult, ahol az adott függvény definiálva volt. Egy példa:
module Part01 where
class Persons p where
getName :: p -> String
getAge :: p -> Int
data Person = Pers String Int
instance Persons Person where
getName (Pers n a) = n
getAge (Pers n a) = a
--end of Part01
module Part02 where
import Part01
class Persons s => Students s where
getID :: s -> Int
data Student Stud String Int Int
instance Persons Student where
getName (Stud n a i) = n
getAge (Stud n a i) = a
instance Students Student where
getID (Stud n a i) = i
--end of Part02
module Project where
import Part01
import Part02
--end of Project
Egyszerűen ellenőrizheted, mi történik, ha lefelejted az egyik import-sort. Csak tedd megjegyzésbe a második sort a 'Part02.hs'-ben és töltsd be újra a 'Project.hs' fájlt! Biztosan hibaüzenetet fogsz kapni.
Összegzés: A modularizáció számos okból előnyös a funkcionális programozásban. A programegységek kisebbek lesznek és ezáltal könnyebben kezelhetőek; a különböző modulok közötti kapcsolatok átláthatóak, világosak a későbbi felhasználás és a hibakeresés során is; valamint csak a projektfájl betöltésével kényelmesen betölthető az összes felhasznált fájl.
Felhasznált irodalom:
[1] A "Hello" egy sztring. A Pascal-hoz hasonlóan a Haskell is idézőjelekkel adja meg egy sztring elejét és végét. Az egyedülálló karakterek aposztrófok között vannak. Sztring: "abc"; karakterek: 'a', 'b', 'c'.
[2] A windows-os verzióban használhatod a script (szöveg) menedzsert új fájlok betöltésekor - csak válaszd az 'Add script'-et (szöveg hozzáadása), válaszd ki a fájlt, majd kétszer klikkelj az 'Ok' gombra. Ha a DOS-os verziót használod, akkor meg kell változtatnod az aktuális elérési útvonalat (path) (':cd ...') és töltsd be a fájlt a következő utasítással: ':l "FileName.Ext"'.
[3] Ha Pascal függvényt írnánk, ezt így olvasnánk: function Increment (i : Integer) : Integer
[4] Ezt a koncepciót polimorfizmusnak hívják. Bővebb információk az 5. részben.
[5] vagy elemei, ha több kifejezést rakunk szögletes zárójelek közé vesszőkkel elválasztva
[6] Ebben a segédletben nem mutatjuk be a lambda-kifejezéseket. Ez a definíció csak azért került a többi közé, mert a Haskell beépítetten ezt a definíciót használja.
[7] Az osztályokról és példányaikról ld. bővebben a 8. fejezetben.