
Haskell nyelvben minden gráfbeli pontnak (kifejezésnek) és minden gráf-újraírási szabálynak (függvénynek) van típusa. Haskellben a beépített típusok semmiben sem különböznek a saját adattípusoktól. A típusok osztályokba vannak sorolva, és ez alól az egyszerű beépített típusok sem kivételek. Íme, a beépített típusok hierarchiája
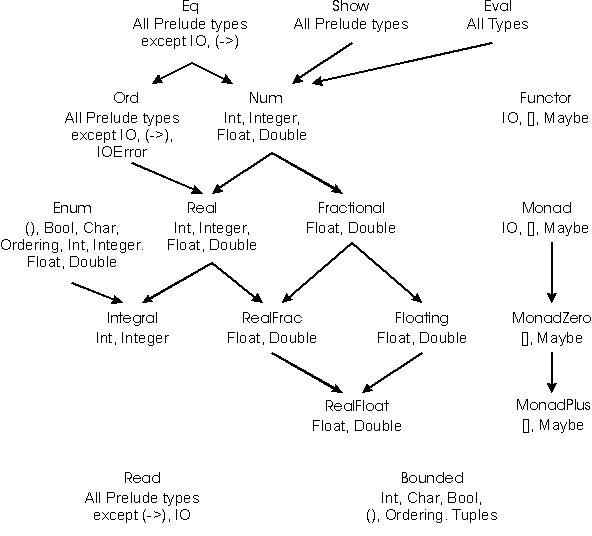
A Show osztályba tartozó típusok megjeleníthetők, a Read osztálybeliek beolvashatók, az Eq osztályba tartozókra van egyenlőségvizsgálat, az Ord típusúak rendezettek is.
A leggyakoribb hiba a típushiba. Egyesek szerint a funkcionális nyelvek esetén minden hiba ilyen jellegű. A fordító ilyen esetekben rögtön figyelmeztet bennünket.
Elemi
Egész szám típus
| Típus | Osztály | Leírás |
| Integer | Integral | Tetszőleges méretű egész |
| Int | Integral | Rögzített méretű egész |
Logikai típus
data Bool = False | True
A Bool típus felsorolási típus, a Read, Show, Eq, Ord, Enum és Bounded osztályok példánya. Az alap logikai műveletek jelölései: && (és), || (vagy), és not.
Karakter típus
A Char típus felsorolási típus és 16 biten tárolható, megfelelője a szabványos Unicode. A Char típus a Read, Show, Eq, Ord, Enum, és Bounded osztályok példánya.
String típus
A string karakterek listája:
type String = [Char]
Példa:
"A string" = [ 'A',' ','s','t','r', 'i','n','g']
Valós szám típus
| Típus | Osztály | Leírás |
| (Integral a) => Ratio a | RealFrac | Racionális számok |
| Float | RealFloat | Egyszeres pontosságú, valós, lebegőpontos számok |
| Double | RealFloat | Dupla pontosságú, valós, lebegőpontos számok |
| (RealFloat a) => Complex a | Floating | Complex, lebegőpontos számok |
Összetett
Mutató típus
Haskellben nincs pointer vagy referencia típus.
Beépített típuskonstrukciók
Ezek tulajdonképpen magasabb rendű típusok; típus konstruktoraikat elsőrendű típusokkal paraméterezve kapunk közvetlenül felhasználható típuspéldányokat. Ilyen magasabb rendű típus a lista, tuple, és a unit típus.
Lista típus
data [a] = [] | a : [a]
A listák algebrai adattípusok két konstruktorral. Az első konstruktor az üres lista [], és a második a (:) . A lista a Read, Show, Eq, Ord, Monad, és MonadPlus osztályok példánya. Így tehát változó hosszúak, viszont csak azonos típusú elemeket tartalmazhatnak (homogének). [a,b,c] alakú jelölésük mindössze szintaktikus cukor az a:b:c:[] láncra.
Listát definiálhatunk egy nagyon hatékony módon, hasonlóan a matematikai halmaz definíciókhoz, pl:
[ (x,y) | x <- xs, y <- ys, y > x ]
Ez tulajdonképpen megfelel egy ciklusnak, az értelmezési tartományokat balról jobbra egymásba ágyazva, tehát leggyorsabban a legjobboldali halmaz (jelen esetben ys) elemeit cseréljük, ez határozza meg a lista elemeinek sorrendjét. Számok listáit a határokkal is meg lehet adni, a határok közé ".." kerül. Ilyenkor az első két elem határozza meg a lépésközt, ha pedig a ".." előtt csak egy szám van, akkor onnantól kezdve egyenként halad.
Tehát pl.:
[ (x,y) | x <- [3..8], y <- [2,4..9], y > x ] =
[(3,4),(3,6),(3,8),(4,6),(4,8),(5,6),(5,8),(6,8),(7,8)]
Ha a ..-nak nem adunk meg az egyik oldalon határt, akkor abban az irányban végtelen.
Sor típus
A sor algebrai adattípus, konstruktorai a (,) (,,), és így tovább... Minden sor az Eq, Ord, Bounded, Read, és Show osztályok példánya. A sor konstruktorát kétféleképpen is írhatjuk: prefix jelöléssel, és a hagyományos módon, azaz:
(,) x y = (x,y)
A sor tehát tulajdonképpen egy n-es, azaz adott hosszúságú tömb, ami azonban lehet heterogén (azaz tartalmazhat különböző típusú elemeket).
A unit típus
data () = () deriving (Eq, Ord, Bounded, Enum, Read, Show)
A unit típusnak egyetlen adatkonstruktora van a (), azaz ez az egyetlen típusérték.
Tömb típus
A Haskell'98 még csak egy tömb konstruktor típust támogatott, az Arrayt, ami immutábilis, boxed tömböket valósít meg.
Immutábilisek, azaz nem módosíthatóak, mint a többi tiszta funkcionális adattípus; tartalmuk létrejöttükkor rögzül, és csak olvasható. Léteznek "módosító" műveletek, de ezek új tömböket hoznak létre, az eredeti módosítása nélkül.
Ez lehetővé teszi a tömbök használatát tisztán funkcionális kódban.
Boxed, azaz bedobozolt értékek lehetnek a tömb elemei, azaz rendes lustán kiértékelt Haskell típusok, és még definiálatlan (_|_) értéket is tartalmazhat.
Napjaink Haskell fordítói a tömbök új implementációját tartalmazzák, amik visszafelé kompatibilisek a Haskell'98 tömbjeivel, de sokkal több lehetőséget biztosítanak.
Nézzük meg a Haskell'98 Array típusának használatát:
Az Array típus a Data.Array modul importálásával érhető el.
Az array függvény segítségével hozhatunk létre új tömböket. Az array függvény szignatúrája:
array :: Ix i => (i, i) -> [(i, e)] -> Array i e
A függvény első paraméterként indexek párját várja, ami megadja a tömb indexelési tartományát. Az index típusa az Ix típusosztály eleme kell hogy legyen.
A második paraméter az eltárolandó index-elem párok listája.
arr = array (1,3) [(1,2),(2,5),(3,7)]
Ha a tömbnek olyan indexű elemet adunk meg, ami nem szerepel az indextartományban, akkor a lista értéke _|_ lesz.
Ha egy indexhez többször, vagy egyszer sem rendelünk értéket, akkor értéke _|_ lesz.
Ha az indextartomány alsó határa nagyobb mint a felső, a tömb érvényes, de üres lesz.
Az elemek eléréséhez a ! operátort használhatjuk. Szignatúrája:
(!) :: Ix i => Array i e -> i -> e
Az előző tömbre például:
arr ! 3 == 7
A lusta kiértékelésnek köszönhetően a tömb létrehozása közben már hivatkozhatunk rá. Itt látható erre két példa:
fact = array (1,10) ((1,1) : [(i, i * fact ! (i-1)) | i <- [2..10]])
-- fact ! 5 == 120
fib = array (1,10) ((1,1) : (2,1) : [(i, fib ! (i-2) + fib ! (i-1)) | i <- [3..10]])
-- fib ! 10 == 55
A tömb elemeit a // operátorral frissíthetjük. Egy lépésben több elemet frissít. Szignatúrája:
(//) :: Ix i => Array i e -> [(i, e)] -> Array i e
Az első paraméter a frissítendő tömb, a második pedig a módosítandó index-érték párok listája, az új értékekkel.
arr' = arr // [(1,1),(3,3)]
-- arr' ! 3 == 3
Származtatott, derivált tömböket hozhatunk létre az fmap és ixmap függvényekkel.
fmap :: Functor f => (a -> b) -> f a -> f b
Az fmap függvénnyel egy tömbre elemenként alkalmazhatunk egy függvényt.
doubleArr = fmap (* 2) arr
-- arr ! 2 == 5
-- doubleArr ! 2 == 10
ixmap :: (Ix i, Ix j) => (i, i) -> (i -> j) -> Array j e -> Array i e
Az ixmap függvénnyel átindexhetünk egy tömböt.
shiftedArr = ixmap (lob-1, hib-1) (+ 1) arr
where (lob, hib) = bounds arr
-- arr ! 1 == 2
-- cArr ! 0 == 2
Eddig az indexek egész számok voltak, de bármilyen típus lehet, ami az Ix típusosztály eleme, vagy amire példányosítjuk a típusosztályt. Az Ix elemei például rendezett n-esek is, öt hosszúságig. Ennél hosszabb rendezett n-essel is indexelhetünk tömböket, de ebben az esetben magunknak kell példányosítani.
Példa kétdimenziós tömbre:
A tömb (x,y) indexű helyére x*y-t tesszük, gyakorlatilag szorzótáblát kapunk.
mul = array ((1,1), (10,10)) [((x,y), x * y)| x <- [1..10], y <- [1..10]]
-- mul ! (3,4) == 12
MArray és STArray
A Haskell Platform Data.Array.IO és Data.Array.ST moduljaiban találhatjuk meg az MArray és STArray tömbtípusokat. Az MArray kizárólag IO monádon belül használható, módosítható (mutábilis) tömb. Műveletei mellékhatással járnak, ezért használható csak az IO monádban.
Mivel módosítása nem igényli újabb tömb létrehozását, hatékonyabb, azonban fel kell hozzá adnunk a mellékhatásmentességet és a funkcionális tisztaságot.
Példa használatára:
import Data.Array.IO
import Control.Monad
main :: IO Int
main = do
marr <- newArray (1,10) 0 :: IO (IOArray Int Int)
forM_ [1..10] (\i -> writeArray marr i (i * 2))
a <- readArray marr 6
b <- readArray marr 3
return (a + b)
Ez a program létrehoz egy marr nevű MArray-t, 1-től 10-ig indexelve, nullára inicializálva minden értéket, majd minden indexhez beírja az index kétszeresét. Az a és b azonosítókhoz köti a tömb hatodik és harmadik elemét, majd az összegüket IO monádba injektálja a return függvény segítségével. (Monádokról részletesebben a róluk szóló fejezetben.)
A Haskell STArray tömbjei azonban lehetőséget adnak, hogy mutábilis tömböket használjunk tiszta függvényekben. Ezt úgy éri el, hogy a tömböt módosító mellékhatásos műveleteket az ST monádba zárja, csak azon belül használhatóak.
Felhasználó által definiált típusok
A fenti típusok kombinációit nevesíthetjük a type paranccsal, pl.
type ListaFuggvenyPar = ([Integer], Char -> String)
Figyeljünk rá, hogy a típusnév mindig nagybetűvel kezdődik. Sablon típust úgy hozhatunk létre, hogy a típusnak paraméterként (kisbetűs) szimbólumokkal adjuk meg a sablonparamétereket, és a definícióban ezeket használjuk fel, tehát pl. a
type AssocList a b = [(a,b)]
definíció a és b típusú párok listájának felel meg.
A Haskellben is lehet felsorolási típust, rekord (direkszorzat) típust, variáns rekord (unió) típust és rekurzív típust készíteni. Az új típusokat a data kulcsszóval kell bevezetni, ezután következik a típuskonstruktor (a típus neve), majd pedig az adatkonstruktorok, mindegyiket nagybetűvel kezdjük.
Egy példa a felsorolási típus definiálására:
data Color = Red | Green | Blue
Ebben a példában a konstruktorok mind nullárisak, és egy felsorolási típust kaptunk eredményül. Érdekesség, hogy egy felsorolási típus elemeit fel is lehet sorolni:
[Red..Blue] ===> [Red, Green, Blue]
Egy példa variáns rekord (unió) típus definiciójára:
data Tagger = Tagn Integer | Tagb Bool
Egy példa rekord típus definiciójára :
data Point a = Pt a a
Az ilyen, egyetlen adatkonstruktorral rendelkező típusoknak kitüntetett szerepe van abban az értelemben, hogy így kaphatunk rekordokat. Point egy polimorf típus: van egy típusparamétere, a rekord pedig két ilyen típusú elem direktszorzata.
Az adat- és típuskonstruktorok különböző namespace-ben vannak, ezért lehet ugyanaz a nevük:
data Point a = Point a a
Ez a gyakorlati felhasználásban nagy könnyebbség, de azért nem árt, ha tisztában vagyunk vele, hogy épp melyiket is használjuk.
Egy példa rekurzív típus definíciójára :
data Tree a = Leaf a | Branch (Tree a) (Tree a)
Megfigyelhetjük, hogy az előbbi típuskonstrukciókban az egyes mezőknek nincs neve. Természetesen ez is megoldható:
data Circle = Cir {pointx, pointy :: Float, radius :: Float}
És a használat, ha c egy Circle típusú változó:
pointx c
A Haskell is ismeri még a rendezett pár típust is. Elvileg ezek a típusok is leírhatók az előbbi típuskonstrukciós eszközökkel, de ezeket a Haskell beépítve ismeri.
További érdekesség, hogy a struktúrák - például listák - mérete tetszőleges (akár végtelen is!) lehet. A struktúra elemeit nem kötelező mind inicializálni - nyilván, végtelen esetben ez kényelmetlen lehetne . A nem inicializált elemeket viszont nem lehet lekérdezni.
Tömbök típuskonstrukciós eszközök használatával jönnek létre, és nem egy kulcsszó használatával. A tömbök használatában az értékadás nem destruktív, ezért egy tömb elemenként való feltöltése rendkívül sok memóriát fogyaszt. Természetesen erre is van megoldás, a Haskell támogatja a tömbök monolitikus kezelését. A tömbök indexére nem kényes a Haskell, egyetlen kikötés, hogy az indexelő típus tartozzon az Ord osztályba
Típusszinonimák, altípusok
Másik eszköz új típusok létrehozására a már meglevő típusok átnevezése. A Haskell kétféle módon tud átnevezéssel típust létrehozni: a típusszinonimák ugyanazt a típust nevezik meg, itt tehát csak egy aliasról van szó, a másik esetben pedig egy teljesen új típus jön létre, aminek ugyanaz a szerkezete.